-
持续集成——构建接口自动化测试的一种解决方案
2020-07-24 10:55jenkins还有很多实用的功能,有时间可以去研究下jenkins的pipeline,然后再来个分享。给你打电话。😁 😁 😁 😁
-
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55虽然好多写答案的了,还是把自己写的代码贴上来,毕竟写了很久。虽然判断重名的还没有实现
import os import hashlib class Test: #获取文件对应的md5 def get_md5(self,path,file_name): with open(os.path.join(path,file_name),'rb') as f: md5obj=hashlib.md5() md5obj.update(f.read()) hash=md5obj.hexdigest() return hash #获取文件大小的函数,默认获取到的单位是byte def get_size(self,file_path): fsize=os.path.getsize(file_path) fmz=fsize/1024 #转换为kb return round(fmz,2) #过滤重名文件并重命名 def rename(self,path): list = [] # 定义一个空列表用来存放文件名 i = 1 # 重名文件-文件名自增 for root, dirs, files in os.walk(path): for file in files: if file not in list: # 判断文件名是否已经在列表中,如果不在,则直接追加 list.append(file) else: # 如果在,则重命名后追加 new_name = "test000" + str(i) + ".py" # 新文件名命名组合 os.rename(file, new_name) list.append(new_name) i += 1 # print("每一次的list是{}".format(list)) return list # 返回重命名后的文件集合 # 获取目录下的所有文件,并调用get——md5函数 def allfile(self,basepath): # 判断是否有重名文件并重命名,调用rename函数 self.rename(basepath) list1=[] for root,dirs,files in os.walk(basepath): for file in files: #获取文件的大写 fsize=self.get_size(os.path.join(root,file)) if fsize>1: #如果文件大于1kb,则修改名称 md5_name = self.get_md5(root, file)+".py" #md5名字:root:文件对应目录;file:文件名 os.rename(file,md5_name) #将大于1kb的文件重命名 print("符合条件的所有文件是{},文件大小是{}kb".format(file,fsize)) else: # print("文件{}太小,大小是{}byte".format(file,fsize)) list1.append(file) print("小于1kb的文件集合是{}".format(list1)) if __name__ == '__main__': path=os.getcwd() Test().allfile(path)1)一共4个方法:过滤重名文件并重命名,获取文件对应的MD5,获取文件大小,获取文件列表(判断大小&重命名)
2)主要用到了os库中的 os.path.getsize(), walk(), os.path.join(), os.rename() 函数。中间使用了for循环和if判断
3)关于获取文件md5的代码是直接在网上搜的,自己看不太明白。 -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55import os import hashlib import uuid def get_all_file(file_path): files = [ file for root,dir,files in os.walk(file_path) for file in files if os.path.getsize(os.path.join(root,file))>10485760] md5_file_name = {get_md5(filename+str(uuid.uuid1())):filename for filename in files} print(md5_file_name) return files def get_md5(filename_index): secret = hashlib.md5() secret.update(filename_index.encode("utf-8")) return secret.hexdigest() if __name__ == '__main__': **print(get_all_file('filepath')) -
20181210Python 自动化笔试题,挑战你的知识库
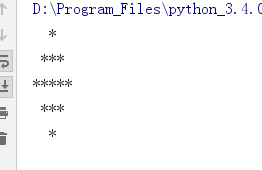
2020-07-24 10:55早上花了差不多一个小时,才搞出来,如果面试,啊,磨磨唧唧肯定写不出来。主要是算空格 * 和行的关系。代码中区分了n为奇数或偶数的情况。附上代码

-
20181210Python 自动化笔试题,挑战你的知识库
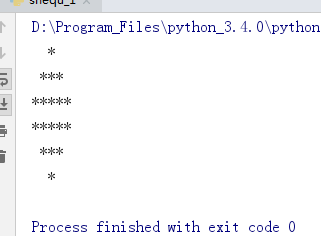
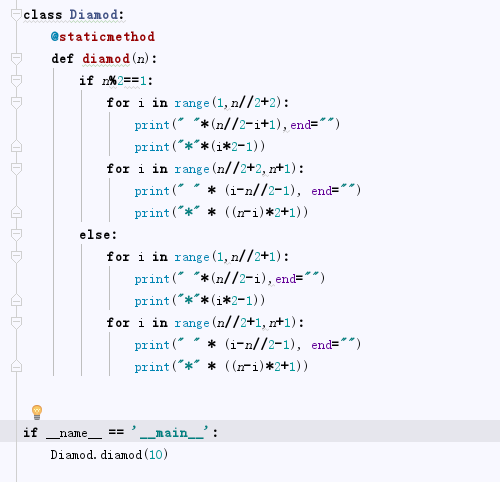
2020-07-24 10:55早上花了差不多一个小时,才搞出来,如果面试,啊,磨磨唧唧肯定写不出来。主要是算空格 * 和行的关系。代码中区分了n为奇数或偶数的情况。附上代码:
n=9时:
n=10的时候:
-
20181210Python 自动化笔试题,挑战你的知识库
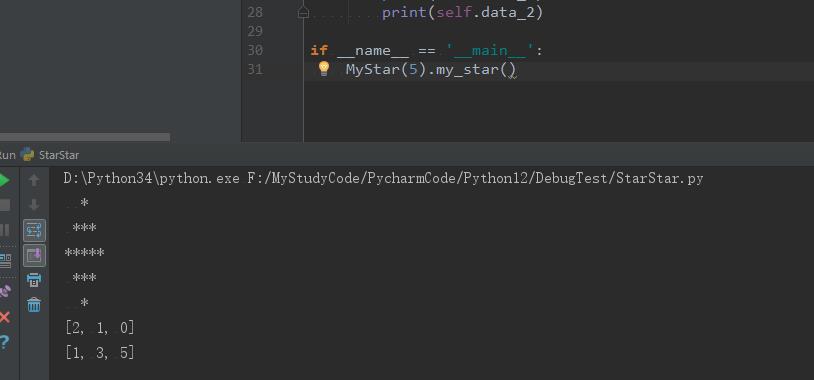
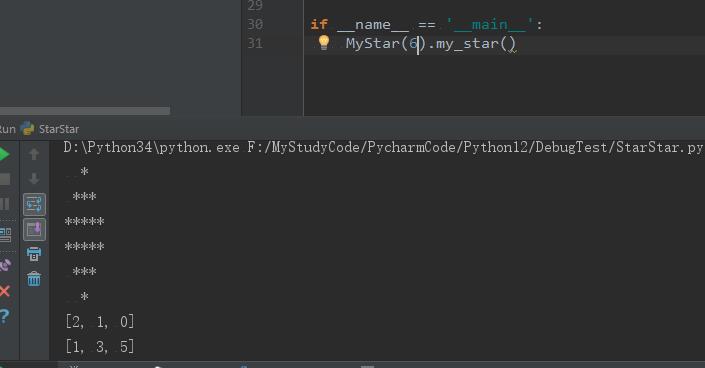
2020-07-24 10:55# -*- coding: UTF-8 -*- # @Author: Sai_Python12 # @Email: 932934045@qq.com # @File: StarStar.py class MyStar: '''星星类''' def __init__(self, n): self.n = n self.data_1 = [] #存放上半部左侧空格数量 self.data_2 = [] #存放上半部星号数量 def my_star(self): K = int((self.n+1)/2) #K 为上部一半 for i in range(1, K+1):#i 为行数 self.data_1.append(K-i) self.data_2.append(2*i-1) print(' '*self.data_1[i-1] + '*'*self.data_2[i-1]) if self.n % 2 == 0: for i in range(1, K+1): print(' '*self.data_1[-i] + '*'*self.data_2[-i]) else: for i in range(1, K): print(' '*self.data_1[-i-1] + '*'*self.data_2[-i-1]) print(self.data_1) print(self.data_2) if __name__ == '__main__': MyStar(6).my_star()
-
20181210Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55几年前学c++写的这个
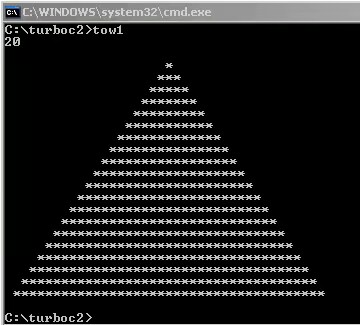
这个是更久之前用turboc C写的
这个是用易语言写的demo
代码~~ 可能早到没了吧
不会python,蹭一下回复,想起夕阳下的奔跑,那是我逝去的青春ԅ(¯ㅂ¯ԅ)
-
python 之 unittest+ddt
2020-07-24 10:55写得很不错呢,什么时候我也把学的总结下。你可以用这个 HTMLTestRunnerNew 库,个人感觉这个好看一点,华华大佬也是用的这个,你可以尝试下。😁
链接:https://pan.baidu.com/s/1NqlA8gD8eb1S9rBPutWU8g
提取码:5puw -
python 之 unittest 初探
2020-07-24 10:55如果太多不懂的话,我就考虑着把整理一份详细的思路。代码这个东西,重在思路,其他的熟悉就完事了。刚入门python的话,基础要打好哦
-
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55import os,hashlib md5_list=[] class GetFile: def get_md5(self,file): if os.path.isfile(file): f = open(file,'rb') md5_obj = hashlib.md5()#获取一个md5加密算法对象 md5_obj.update(f.read())#读取文件,制定需要加密的字符串 hash_code = md5_obj.hexdigest()#获取加密后的16进制字符串 f.close() md5=str(hash_code).lower()#转为小写 return md5 def alter_file(self,directory): list_dir=os.listdir(directory)#获取指定目录下的文件 for item in list_dir:#遍历目录下的文件 files_md5=self.get_md5(item) md5_list.append(files_md5) md5_set=set(md5_list) for i in md5_set: #判断md5个数是否大于1,做去重 if md5_list.count(i)>1 and os.path.getsize(item)>10*pow(1024,2):#判断文件的大小是否大于10M file=os.path.splitext(item)#将文件拆成文件名和后缀 file_new=files_md5+file[1]#命名一个新文件 try: os.rename(item,file_new)#文件替换 print("符合的文件有{0},修改为{1}".format(item,file_new)) except FileExistsError as e: print(e) break if __name__ == '__main__': #指定一个目录 path="F:\Python\python" GetFile().alter_file(path) -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55import os import hashlib class MyFile: '''文件夹类''' def __init__(self, myPath): self.rootPath = myPath def del_files(self): '''遍历文件夹''' for root, dirs, files in os.walk(self.rootPath):#逐层遍历文件夹 for file in files:#遍历每一个文件 File1.append(os.path.join(root, file))#每一个文件放在总的列表下 fileSize = os.path.getsize(os.path.join(root, file)) if fileSize >= 10*1024*1024: File2.append(os.path.join(root, file)) #文件名去重 for item in File1: if item not in File3: md = self.get_file_md5(item) File3.append(item) else: self.get_file_md5(item) File4.append(md) def get_file_md5(slef, filename): '''得到每个文件的md5''' md5 = None if os.path.isfile(filename): f = open(filename, "rb") fileMd5 = hashlib.md5() fileMd5.update(f.read()) hashCode = fileMd5.hexdigest() f.close() md5 = str(hashCode).lower() return md5 else: print("这不是一个文件,请重新确认路径。") return if __name__ == '__main__': File1 = [] # 获取所有带路径文件名 File2 = [] # 获取大于10M的带路径文件名 File3 = [] # 获取去重后的带路径文件名 File4 = [] # 存放重复名字md5 myFile = MyFile(r'C:\Users\admin\Desktop\柠檬班书籍') myFile.del_files() print("File1:", File1) print("File2", File2) print("File3", File3) print("File4", File4) -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55import os import hashlib def filename_distinct(file_path): #获取目录下的所有文件并去重 files=[] for root, dirs, file in os.walk(file_path): '''file为循环遍历的每一个目录下的文件,存储为列表形式''' files+=file #每个文件夹下的文件名列表相加,获取所有文件 #对所有文件名去重并重命名重复的文件名,循环遍历,两两对比 for i in range(len(files)-1): for j in range(i,len(files)-1): if files[i]==files[j+1]: #如果文件名重复 '''为重复的文件名中的一个重命名,加上循环遍历的i,j保证重命名后文件名不会再重复''' files[i]=str(i)+str(j)+files[i] # print('所有文件名——去重后:',files) return files def file_md5(file_path): #获取文件的md5属性 if os.path.isfile(file_path): fp = open(file_path, 'rb') contents = fp.read() fp.close() md5_1 = hashlib.md5(contents).hexdigest() else: print('file not exists') return md5_1 def get_big_file(file_path,size): #获取大于指定size的文件,单位为M big_file=[] for fpathe,dirs,fs in os.walk(file_path): #遍历目录下的所有文件 for f in fs: file_path=os.path.join(fpathe,f) #文件的绝对路径 if os.path.getsize(file_path)>1024*1024*size: big_file.append(file_path) #获取到大于10M的文件绝对路径列表 return big_file if __name__ == '__main__': file_path='C:\\Users\\liang\\Desktop\\新建文件夹' bigfile=get_big_file(file_path,10) print(filename_distinct(file_path)) print(bigfile) md5file=[] for file_name in bigfile: md5file.append(file_md5(file_name)) print(md5file) ```python -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55mport os
import hashlibdef filename_distinct(file_path):
#获取目录下的所有文件并去重
files=[]
for root, dirs, file in os.walk(file_path):
'''file为循环遍历的每一个目录下的文件,存储为列表形式'''
files+=file #每个文件夹下的文件名列表相加,获取所有文件
#对所有文件名去重并重命名重复的文件名,循环遍历,两两对比
for i in range(len(files)-1):
for j in range(i,len(files)-1):
if files[i]==files[j+1]: #如果文件名重复
'''为重复的文件名中的一个重命名,加上循环遍历的i,j保证重命名后文件名不会再重复'''
files[i]=str(i)+str(j)+files[i]
# print('所有文件名——去重后:',files)
return filesdef file_md5(file_path):
#获取文件的md5属性
if os.path.isfile(file_path):
fp = open(file_path, 'rb')
contents = fp.read()
fp.close()
md5_1 = hashlib.md5(contents).hexdigest()
else:
print('file not exists')
return md5_1def get_big_file(file_path,size):
#获取大于指定size的文件,单位为M
big_file=[]
for fpathe,dirs,fs in os.walk(file_path): #遍历目录下的所有文件
for f in fs:
file_path=os.path.join(fpathe,f) #文件的绝对路径
if os.path.getsize(file_path)>10241024size:
big_file.append(file_path) #获取到大于10M的文件绝对路径列表
return big_fileif name == 'main':
file_path='C:\Users\liang\Desktop\新建文件夹'
bigfile=get_big_file(file_path,10)
print(filename_distinct(file_path))
print(bigfile)
md5file=[]
for file_name in bigfile:
md5file.append(file_md5(file_name))
print(md5file) -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55# -*- coding:utf-8 -*- import os import hashlib FILE_LIST = [] #所有文件列表 #获取目录下所有文件 def get_file_list(dir_path): global FILE_LIST dir_list = {} if not os.path.isdir(dir_path): print('目录不存在') else: dir_list = os.listdir(dir_path) for file in dir_list: file_path = dir_path + '\\' +file if os.path.isdir(file_path): get_file_list(file_path) #目录包含目录需读得里面的文件 else: FILE_LIST.append(file_path) #print(FILE_LIST) #获取文件的md5的值 def get_file_md5(file_path): def read_chunks(fh): fh.seek(0) chunks = fh.read(8096) #文件过大一块块读 while chunks: yield chunks chunks = fh.read(8096) else: #最后将游标放回到文件头 fh.seek(0) myhash = hashlib.md5() with open(file_path,'rb') as fh: for chunk in read_chunks(fh): myhash.update(chunk) return myhash.hexdigest() #文件大小过滤及重命名 def file_operator(dir_path,size,file_size_unit): count = 0 file_dict = {} get_file_list(dir_path) #获取目录下所有文件 for file in FILE_LIST: file_size = os.path.getsize(file) if file_size_unit == 'Byte': file_size = file_size elif file_size_unit == 'KB': file_size = file_size / 1024 elif file_size_unit == 'M': file_size = file_size / 1024 / 1024 elif file_size_unit == 'G': file_size = file_size / 1024 / 1024 / 1024 else: print('文件单位默认为M处理') ile_size = file_size / 1024 / 1024 file_size = round(file_size,2) file_md5 = get_file_md5(file) #获取文件的md5码 file_path = os.path.split(file) file_full_name = file_path[1] #获取文件的名称,不包含目录 count += 1 file_type = file_full_name[file_full_name.index('.'):] #获取文件的类型 #新目录名 = 目录+文件+文件md5码+记数+文件类型 new_name = file_path[0] + '\\' + str(file_md5) + '_' + str(count) + file_type os.rename(file,new_name) if(file_size > size): #过滤文件大小不足的 file_dict[new_name] = str(file_size) + file_size_unit print('大小超过{0}{1}的文件列表为:\n{2}'.format(size,file_size_unit,file_dict)) if __name__ == '__main__': file_operator(r'G:\test',10,'M') -
20181205Python 自动化笔试题,挑战你的知识库
2020-07-24 10:55import os import hashlib def get_md5(file_path):#计算md5值 with open(file_path, 'rb') as f: md5 = hashlib.md5() while True: b=f.read(8096)#分段读取 if not b: break #如果读取结束了就跳出循环 md5.update(b) hash = md5.hexdigest() return hash #返回文件的md5值 file_list = [] new_file=[] name=[] def find_file(path): #获取所有的文件,并筛选出大于10M的文件 if os.path.isdir(path)==True: for items in os.listdir(path): new_path=os.path.join(path,items) find_file(new_path) else: if os.path.getsize(path) >=10*1024*1024: file_list.append(path) return file_list def find_name(file): #找到重名的文件并修改 new_path=[] name=[] for items in file: name.append(os.path.split(items)) for i in range(len(name)-1): for j in range(i+1,len(name)): if name[i][-1]==name[j][-1]: new_path.append(os.path.join(name[i][0],name[i][-1])) new_path.append(os.path.join(name[j][0],name[j][-1])) for items in new_path: #new_path里面是所有重名的文件路径集合 md5=get_md5(items) file=os.path.split(items)[-1]#获取文件名 newname=md5+'.'+file.split('.')[-1]#拼接新文件名 os.rename(items,os.path.join(os.path.split(items)[0],newname)) #重命名 path=os.getcwd() print(path) file=find_file(path) find_name(file)