前言
以前常用unittest做接口自动化测试,后来想获取单个接口的响应时间,便采用pytest单元测试框架。虽然获得的时间不太准确——因为pytest测试报告的时间是从一个用例开始到结束,其中包括了断言,所以实际时间比响应时间略长。如果从参考的角度看,这个时间虽然不是很准确,但仍有价值
第一个问题:pytest与ddt冲突
如果你想使用pytest,就不能使用ddt做数据驱动了,否则运行时会抛出异常,提示@data不是pytest的一个fixture
这时可以使用pytest的参数化,即下面这种形式:
@pytest.mark.parametrize(argnames, argvalues, indirect=False, ids=None, scope=None)
一般来说,使用最多的是前两个参数,argnames和argvalues:
argnames:用逗号分隔的字符串,表示一个或多个参数名或参数列表/元组
argvalues:是一个列表,让前面的参数argnames依次从中取值用于迭代
@pytest.mark.parametrize("data", all_data)
def test_send_requests(self, data):
if data["method"] == "get":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
elif data["method"] == "post":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
这样的话,我们就解决了第一个问题,即用pytest参数化来代替unittest的数据驱动
第二个问题:测试报告中的用例名字不规范
迫不及待的点了运行,突然发现测试报告中的用例名字很糟糕,这是什么鬼,为什么会这样写?
TestCases/test_my_requests.py::TestMyRequests::test_send_requests[data0]

这样的测试用例名字,第一眼让人感觉很凌乱,因为根本看不出是哪条接口的。如果能将测试用例中的case_id对应的值作为用例名字就比较完美了:
当时我的第一思路是,先去看看测试报告的元素
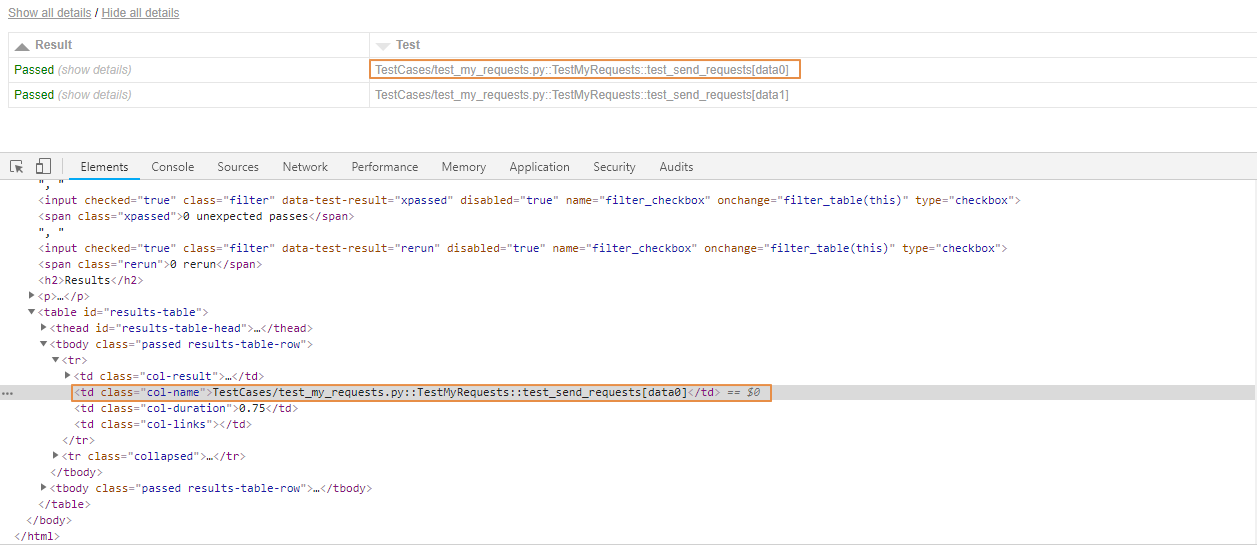
这个用例名字的元素对应的标签的td,对应的class属性值是"col-name",那能不能去pytest-html的源码中看看在哪一块
在其他地方没有找到,但在plugin.py中找到了,可以看到找到了一个,没错就是我们想要的td标签,那么还有一个参数self.test_id是什么?大胆的猜测一下,应该是td标签对应的文本值吧
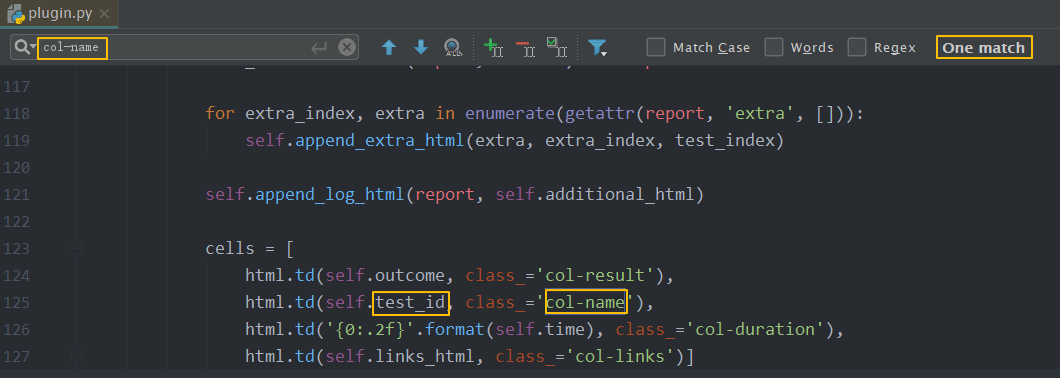
既然要改变td标签的文本值,现在已经猜测是self.test_id对应的值,接下只需搜索一下self.test_id是怎么定义的,一切便迎刃而解
图1

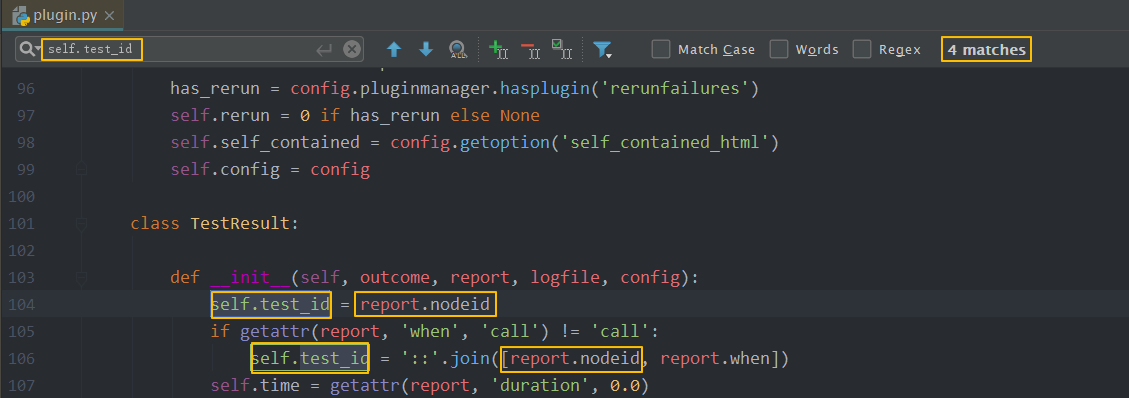
图2

图3

但是真的这么简单吗?请看上图,一共找到了4个self.test_id,除了刚刚我们找的那个,有2个和report.nodeid有关,有1个和extra_index和test_index有关,report.nodeid可能是report的一个属性,而后面两个参数是crate_asset的两个形参,这些东西我们能直接获取到吗?看到这里,感觉第一个思路错了,至少是方向有问题
想想之前,在做unittest的时候,ddt通过修改源码改变用例名字,ddt修改时并不是去HTMLTestRunner中修改的,同理,我们推断下,pytest要修改用例名字,关注点应该是参数化,而不是pytest-html的源码
@ddt.data()
@pytest.mark.parametrize()
这样就获得了第二个思路,去查看parametrize()这个函数的源码,在查看源码过程中,偶然看到另一个函数是这样定义的:
def idmaker(argnames, parametersets, idfn=None, ids=None, config=None, item=None):
ids = [
_idvalset(valindex, parameterset, argnames, idfn, ids, config=config, item=item)
for valindex, parameterset in enumerate(parametersets)
]
if len(set(ids)) != len(ids):
# The ids are not unique
duplicates = [testid for testid in ids if ids.count(testid) > 1]
counters = collections.defaultdict(lambda: 0)
for index, testid in enumerate(ids):
if testid in duplicates:
ids[index] = testid + str(counters[testid])
counters[testid] += 1
return ids
特别是ids[index] = testid + str(counters[testid]),是不是特别熟悉?对了,这个就是测试报告里的[data0],[data1]...而且看看counters的怎么定义的,参数是匿名函数lambda,默认是从0开始
看到这里,大概就比较清楚了,我们最重要的关注点应该是ids,而ids恰好是parametrize()函数的一个参数
def parametrize(self, argnames, argvalues, indirect=False, ids=None, scope=None):
...
:arg ids: list of string ids, or a callable.
If strings, each is corresponding to the argvalues so that they are
part of the test id. If None is given as id of specific test, the
automatically generated id for that argument will be used.
If callable, it should take one argument (a single argvalue) and return
a string or return None. If None, the automatically generated id for that
argument will be used.
If no ids are provided they will be generated automatically from
the argvalues.
...
源码给出的解释是:ids是一个字符串列表或可调用的字符串。如果是字符串列表,则每个字符串对应argvalues,它们是测试id的一部分。如果是None,则会使用自动生成的id。如果是可调用的...
看这么两句就可以了,如果是None,会自动生成用例名字(测试id就是我们说的用例名字),也就是我们看到的[data0],[data1]...,如果有100条用例,那么第100条的用例名字就是[data99],如果是列表,会将列表中的每一次迭代的值作为用例名字
这下我们知道如何修改用例名字了,直接给@pytest.mark.parametrize()添加ids参数就行
do_excel = DoExcel(r"D:\program\workshop\API_AutoTest\TestDatas\API_Datas.xlsx", "test_data")
all_data = do_excel.get_allData()
ids = [ i["case_id"] for i in all_data ]
class TestMyRequests():
...
@pytest.mark.parametrize("data", all_data, ids=ids)
def test_send_requests(self, data):
if data["method"] == "get":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
elif data["method"] == "post":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
...
第三个问题:利用js优化测试用例名字
经过第二步的优化,我们满足了最基本的需求,即想要的用例名字必须是测试用例里自己定义的,而不是一系列默认生成的值

但问题又来了,看报告中前面一长串,真的很不美观,如何去掉前面的TestCases/test_my_requests.py::TestMyRequests::test_send_requests,首先考虑去源码里直接定位,但根据之前的经验,源码里这一串可能就是一个属性的值,你能得到的无非就是类似于report.属性的这种方式,何况,在对pytest和pytest-html运行原理不了解的前提下,这样无疑在浪费时间
这时看到了js,pytest所在位置的resources目录下有个main.js,我们可以通过js来修改td标签中的文本内容
可以在main.js定义一个函数change_testName(),通过split()方法来提取字符串
TestCases/test_my_requests.py::TestMyRequests::test_send_requests[checkUpdate_normal]中的checkUpdate_normal,当然你也可以用正则
function change_testName() {
var td_items = document.getElementsByClassName('col-name');
for (var i = 0; i < td_items.length; i++)
td_items[i].innerHTML = td_items[i].innerHTML.split('\[')[1].split('\]')[0];
}
pytest-html加载js的原理是,它会将resources目录下的main.js中加载到最终的html测试报告的<body>中,这是生成的html报告源码:
</style></head>
<body onLoad="init()">
<script>/* This Source Code Form is subject to the terms of the Mozilla Public
* License, v. 2.0. If a copy of the MPL was not distributed with this file,
* You can obtain one at http://mozilla.org/MPL/2.0/. */
function toArray(iter) {
if (iter === null) {
return null;
}
return Array.prototype.slice.call(iter);
}
function find(selector, elem) {
if (!elem) {
elem = document;
}
return elem.querySelector(selector);
}
function find_all(selector, elem) {
if (!elem) {
elem = document;
}
return toArray(elem.querySelectorAll(selector));
}
...
既然不需要我们主动引入js,只要在main.js中定义好函数就行,但是却发现好像自定义的js函数不起作用
此道不通,必须换另一条道,既然main.js中定义了那么多js函数,我们是否可以将自定义的js语句放到一个已知的函数里面,当然前提是变量不能有重名,不能影响已知函数的功能。找来找去,发现了有个疑似初始化的函数init(),所以放在这个函数里比较合适
function init () {
reset_sort_headers();
add_collapse();
show_filters();
toggle_sort_states(find('.initial-sort'));
find_all('.sortable').forEach(function(elem) {
elem.addEventListener("click",
function(event) {
sort_column(elem);
}, false)
});
};
调整之后的init函数
function init () {
reset_sort_headers();
add_collapse();
show_filters();
toggle_sort_states(find('.initial-sort'));
find_all('.sortable').forEach(function(elem) {
elem.addEventListener("click",
function(event) {
sort_column(elem);
}, false)
});
var td_items = document.getElementsByClassName('col-name');
for (var i = 0; i < td_items.length; i++)
td_items[i].innerHTML = td_items[i].innerHTML.split('\[')[1].split('\]')[0];
};
大功告成:还差点什么
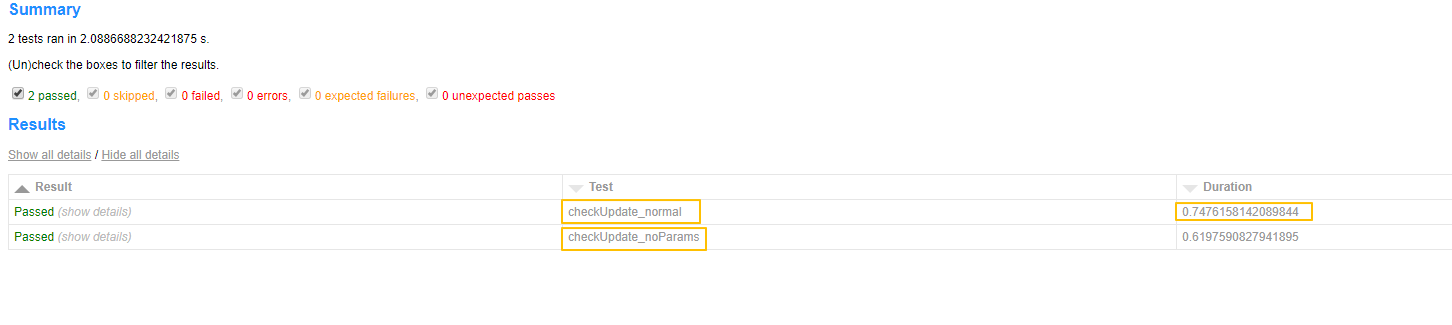
经过运行之后,发现我们的目的已经达到,既可以获得单个接口的测试时间,又调整了用例名字,比原来美观多了
唯一的建议修改源码,最好使用pipenv创建一个虚拟环境,因为多个项目之间共用pytest-html的话,一旦修改了pytest-html源码中的js,那么所有的项目样式都会变。为了保持多个项目依赖库之间不受干扰,请使用虚拟环境
这样,我们的修改就完成了吗?请仔细看我们添加的js代码:
var td_items = document.getElementsByClassName('col-name');
for (var i = 0; i < td_items.length; i++)
td_items[i].innerHTML = td_items[i].innerHTML.split('\[')[1].split('\]')[0];
诚然,当参数化的时候,它没有问题,可是有的场景我们不需要参数化,比如设计一个test_update_normal的测试用例
do_excel = DoExcel(r"D:\program\workshop\API_AutoTest\TestDatas\API_Datas.xlsx", "test_data")
all_data = do_excel.get_allData()
ids = [i["case_id"] for i in all_data]
class TestMyRequests():
...
#单个接口用例
@pytest.mark.parametrize("data", all_data, ids=ids)
def test_send_requests(self, data):
if data["method"] == "get":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
elif data["method"] == "post":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
#场景
def test_update_normal(self, data=all_data[0]):
if data["method"] == "get":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
elif data["method"] == "post":
result = MyRequests().send_request(data["method"], data["url"], params=json.loads(data["request_data"]))
...
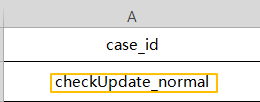
得到的测试报告是这样的:
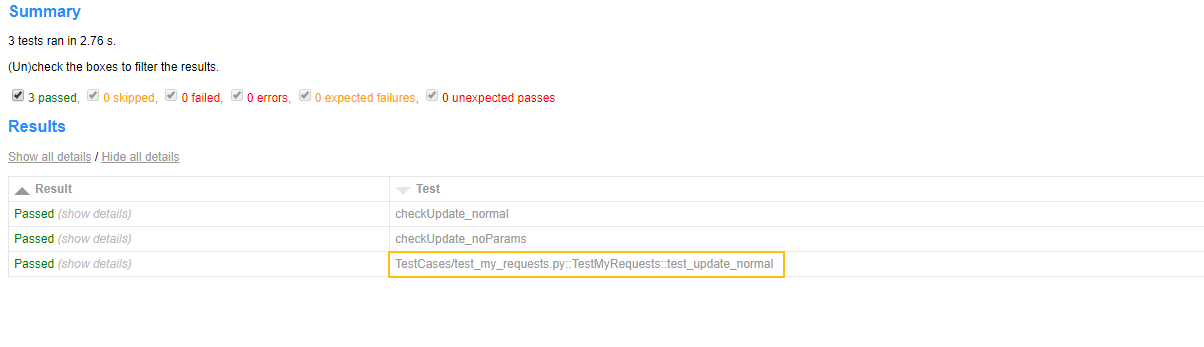
有没有一种很丑的感觉,第3条用例的名字不符合我们的要求,这是因为参数化生成的用例名字包含[],所以我们才能用js对[]做分割,不使用参数化的用例没有[],这时候再去调用js就抛异常了,等于什么都没改变
既然js有异常行为,相应的就该有捕获异常的方法。try...catch这时候可以用起来了,捕获异常,再对异常情况添加处理方式
var td_items = document.getElementsByClassName('col-name');
for (var i = 0; i < td_items.length; i++)
try {
td_items[i].innerHTML = td_items[i].innerHTML.split('\[')[1].split('\]')[0];
}
catch(err) {
td_items[i].innerHTML = 'check' + td_items[i].innerHTML.split('\:\:')[2].split('test_')[1]
}
再次生成的测试报告长这样子:
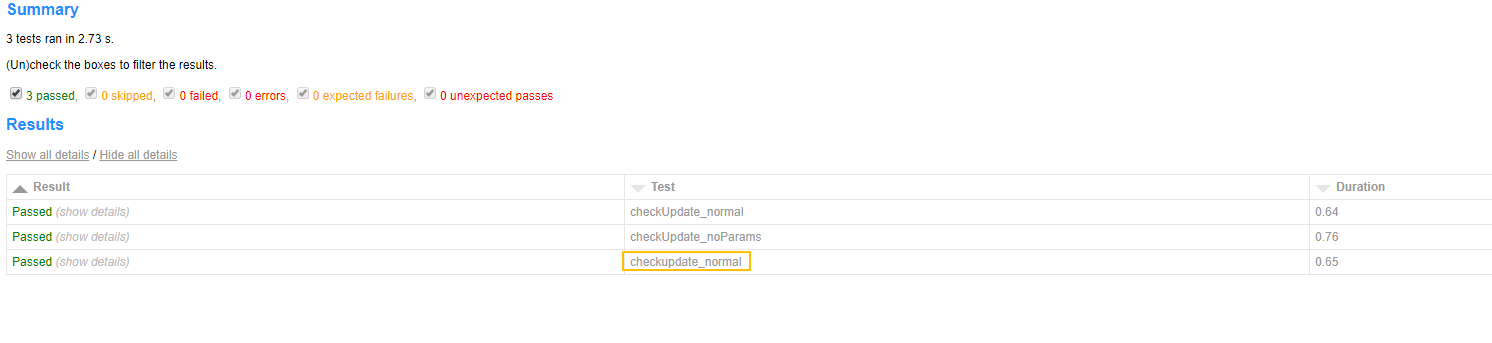
这时感觉用例名字标准多了,我们修改源码,不但要达到基本目的,更重要的是维护源码的健壮性,如果因为修改引起的源码只能在少数情况下使用,那么这样做等于是破坏。另外,再次说明一下,请在虚拟环境下尝试源码修改
欢迎来到testingpai.com!
注册 关于