一直对爬虫感兴趣,学了python后正好看到一篇关于爬取的文章,就心血来潮实战一把吧。
实现目标:抓取豆瓣电影top250,并输出到文件中
1.找到对应的url:https://movie.douban.com/top250
2.进行页面元素的抓取:
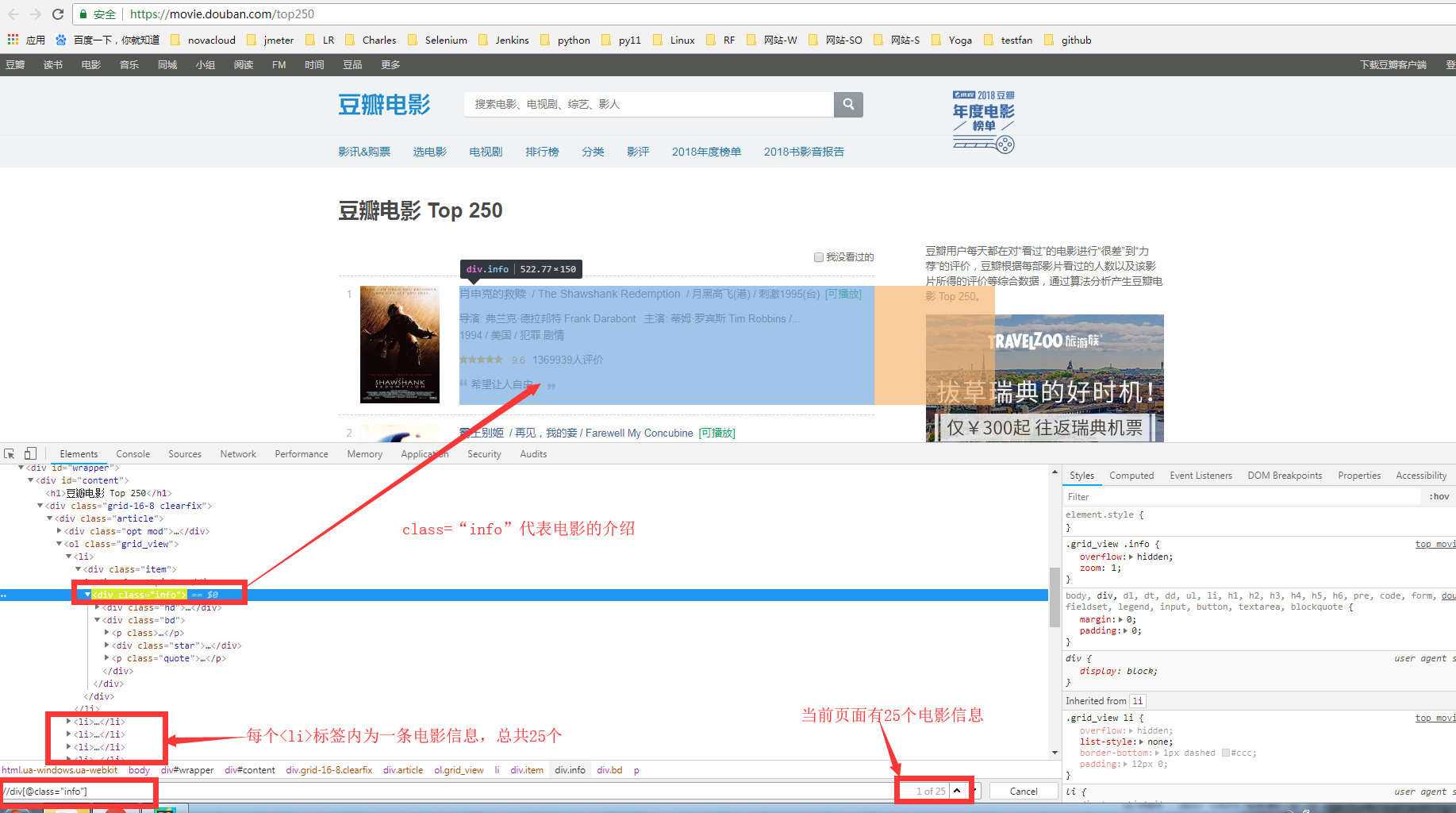
3.编写代码思路:
第一步:实现抓取第一个页面;
第二步:将其他页面的信息也抓取到;
第三步:输出到文件;
4.代码:见最下方
5.执行:执行命令并重定向到TXT文件中:
python xxxx.py >d:/out_test.txt
6.遇到的问题:
1.多页时,for循环的数字设置,来回试几次就可以了,不难。
2.输出到文件中(参照博客:https://www.cnblogs.com/feng18/p/5646925.html,讲的比较详细)

import sys
import io
from selenium import webdriver
#改变标准输出,解决输出到文件时遇到的编码问题。
# 如果输出到控制行,不要加这一行
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030')
class DouBan:
#初始化driver对象,打开页面,最大化页面
def __init__(self):
self.driver=webdriver.Chrome()
self.driver.get('https://movie.douban.com/top250')
self.driver.maximize_window()
# 分页判断,默认显示第一页,输出第一页后,点击下一页按钮,再输出。总共10页
def get_content(self):
for page in range(1,3):
#获取元素定位: 对当前页面中 单个电影元素进行定位
movie = self.driver.find_elements_by_class_name('info')
# for循环:循环输出当前页面中单部影片的电影信息(text输出元素的文本内容);
i = 1
for item in movie:
#输出格式: 电影序号 + 电影介绍 +换行展示
print(str(i+ page*25-25)+": "+item.text+'')
print("")
i+=1
# 判断:如果当前页面码小于10,则查找页码的元素,并点击页码。否则不用进行查找,因为最多点击第10页;
# 获取底部的页签元素(采用了format格式输出,根据当前页面做加1操作)
if page<10:
page_but = self.driver.find_element_by_xpath('//div[@class="paginator"]//a[contains(text(),{0})]'.format(page + 1))
page_but.click()
else:
pass
if __name__ == '__main__':
DouBan().get_content()
欢迎来到testingpai.com!
注册 关于