一、安装
通过命令:pip3 install Beautifulsoup4;
安装后运行:from bs4 import BeautifulSoup,没有报错,说明安装正常;
二、解析库
Beautifulsoup有四种解析方法:
1、BeautifulSoup(markup,"html.parser") 解析速度适中,文档容错能力强
2、BeautifulSoup(markup,"lxml") 解析速度快,文档容错能力强,但是需要安装C语言库
3、BeautifulSoup(markup,"xml") 解析速度快,唯一支持XML的解析器,但是需要安装C语言库
4、BeautifulSoup(markup,"html5lib") 最好的容错性,以浏览的方式解析文档,生成HTML5格式的文档,但是解析速度慢
三、基本使用
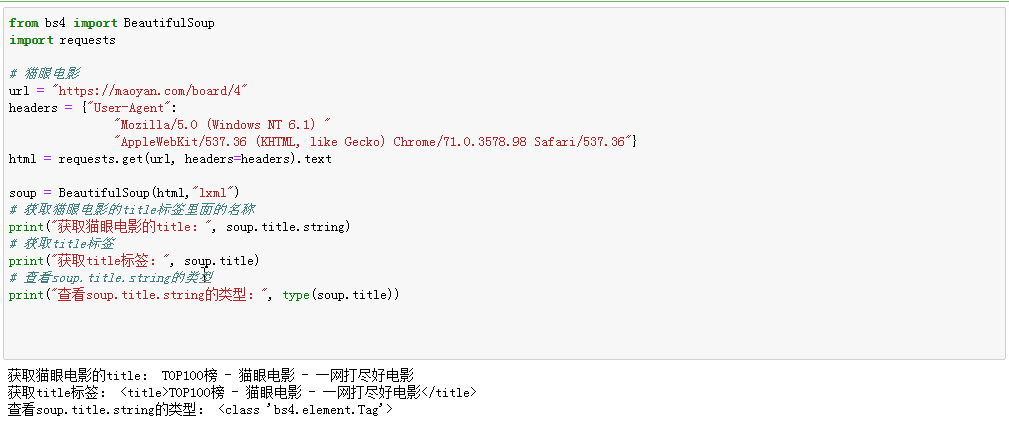
使用type查看获取tag的类型发现,每个标签的类型都是<class 'bs4.element.Tag'>,也就是说通过soup.title这样的形式获取的类型都是Tag类型;
四、常用标签选择器
1、选择元素:与HTML中的标签一样,直接获取对应名称;
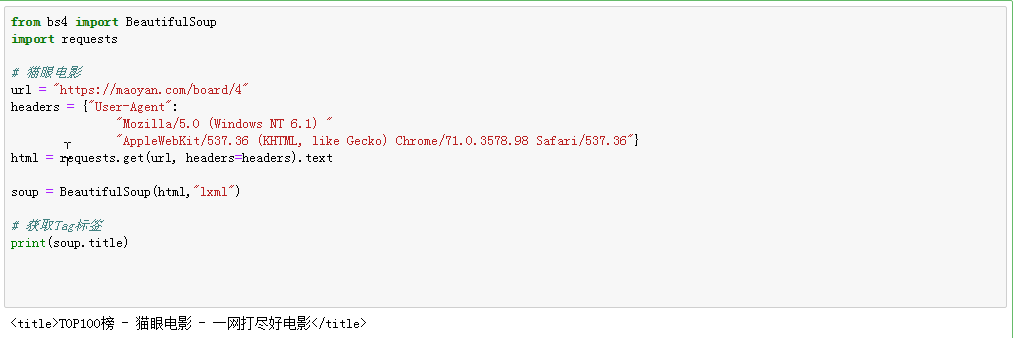
2、获取名称:通过name属性,可以直接获取到标签的名称;
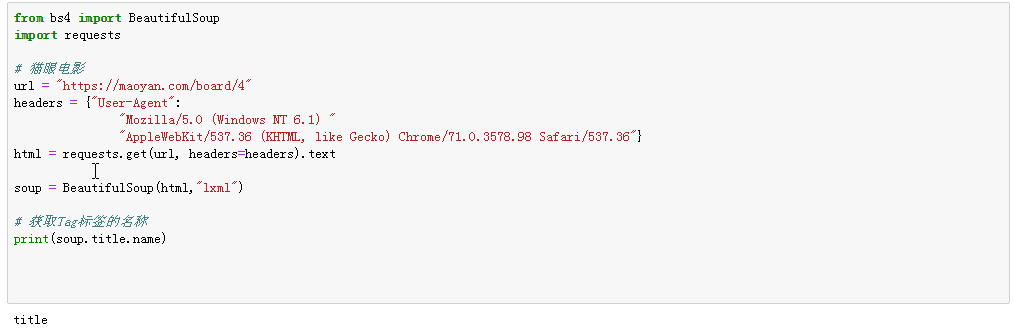
3、获取属性:通过attrs属性获取属性值,或者直接获取属性值;

4、获取内容

5、嵌套选择

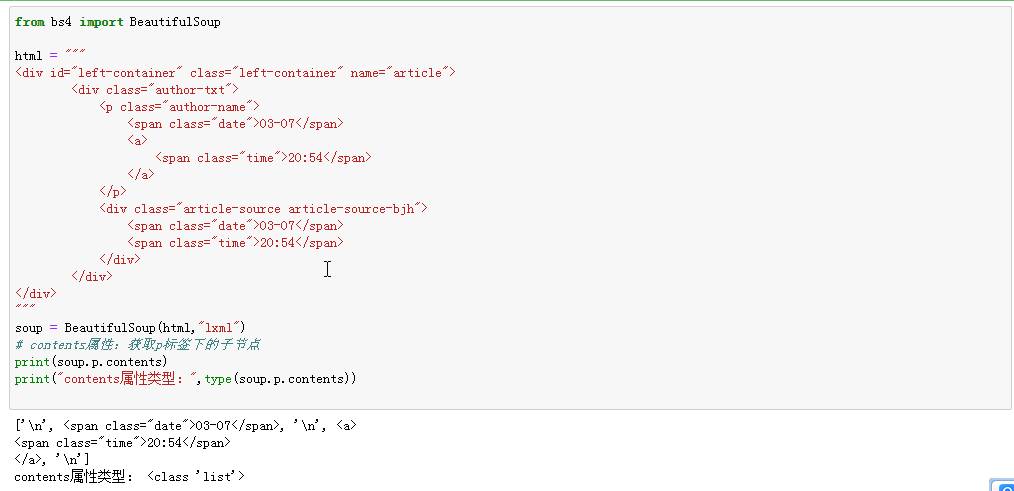
6、子节点:代码中存在层级结构
contents属性:返回形式是列表形式;
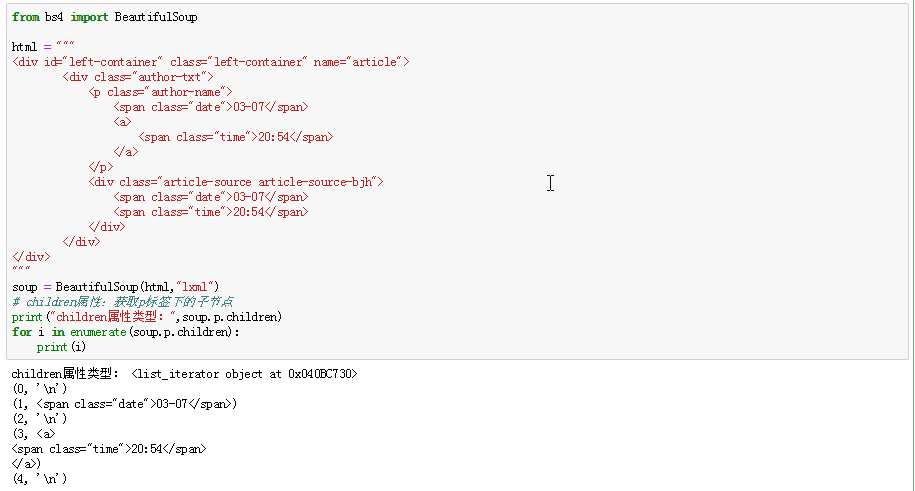
children属性:返回形式是列表类型,需要通过迭代的方式将里面数据取出(使用enumerate属性);
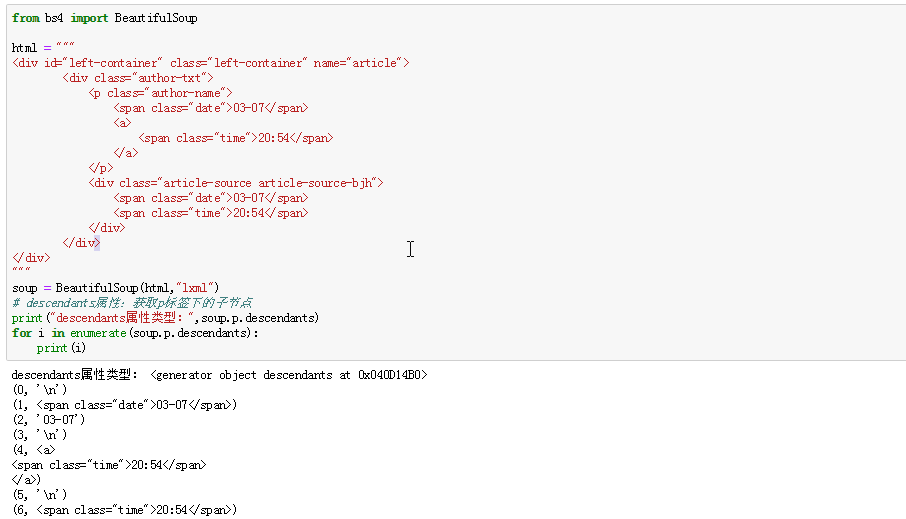
descendants属性:返回形式也是列表类型,但是会将标签页下面的所有节点返回(使用enumerate属性);
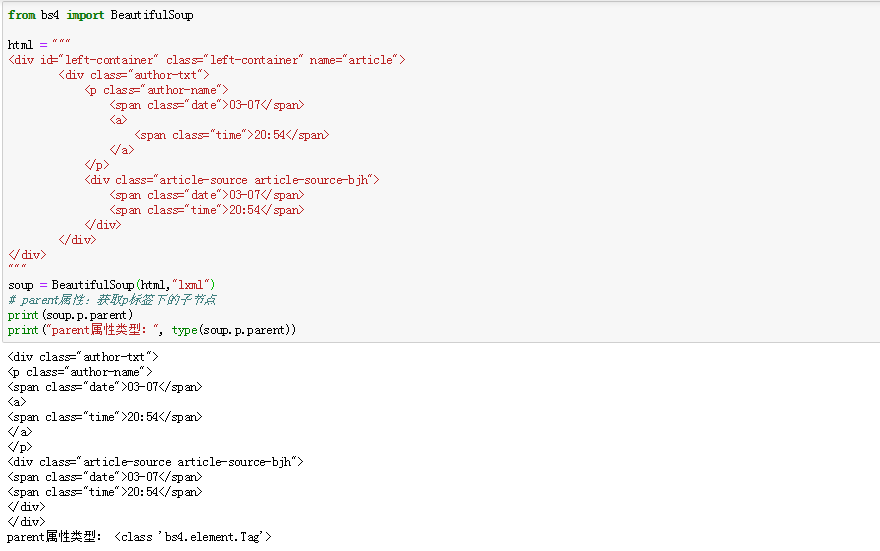
7、父节点:父节点类型是Tag类型;
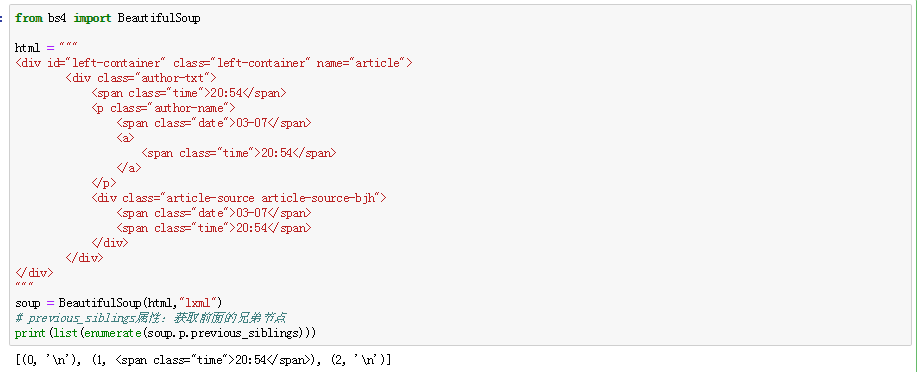
8、兄弟节点:
next_siblings:获取下面的兄弟节点;

previous_siblings:获取前面的兄弟节点;
五、文档树搜索
1、find_all(name, attrs, recursive, text, **kwargs):根据标签名,属性,内容进行查找,返回所有元素;
name:根据标签名查找标签,返回查找的所有元素

attrs:根据属性名进行查找,返回所有元素(注:使用class进行查找元素,因为class在Python中相当于一个关键字,不能当做参数进行使用,需要使用class_当做参数进行使用)
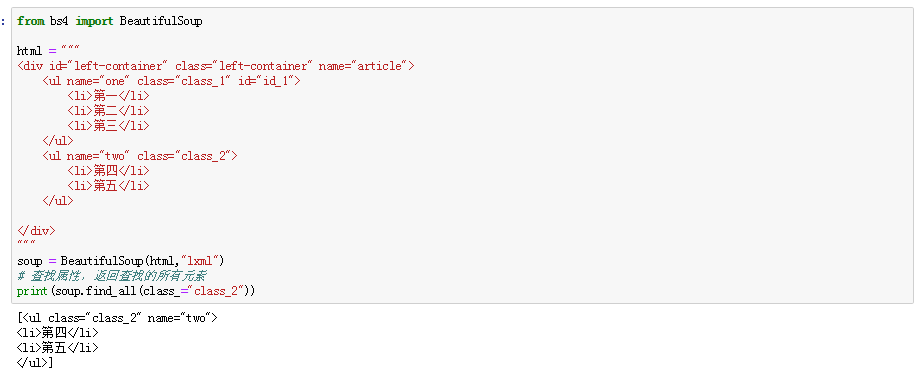
text:根据内容进行查找,返回所有元素
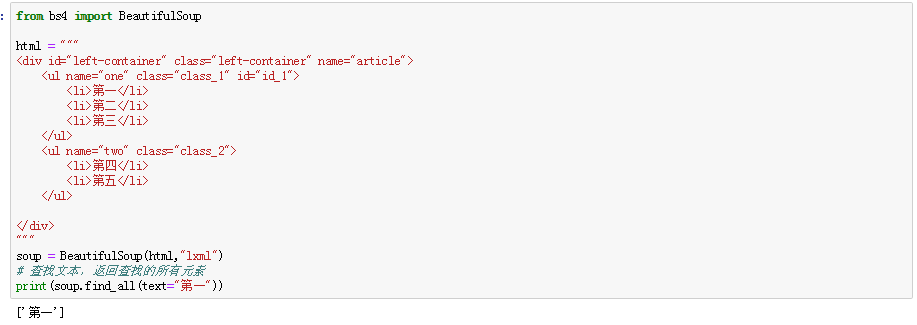
2、find(name, attrs, recursive, text, **kwargs):根据标签名,属性,内容进行查找,返回单个元素;
六、CSS选择器
通过select()直接传入CSS参数即可;

1、获取属性:

2、获取内容:

欢迎来到testingpai.com!
注册 关于