一、主要步骤
1、获取页面源代码
2、使用BeautifulSoup解析页面,获取相关信息
3、循环爬取多个页面
4、写入本地文件中
二、爬取页面
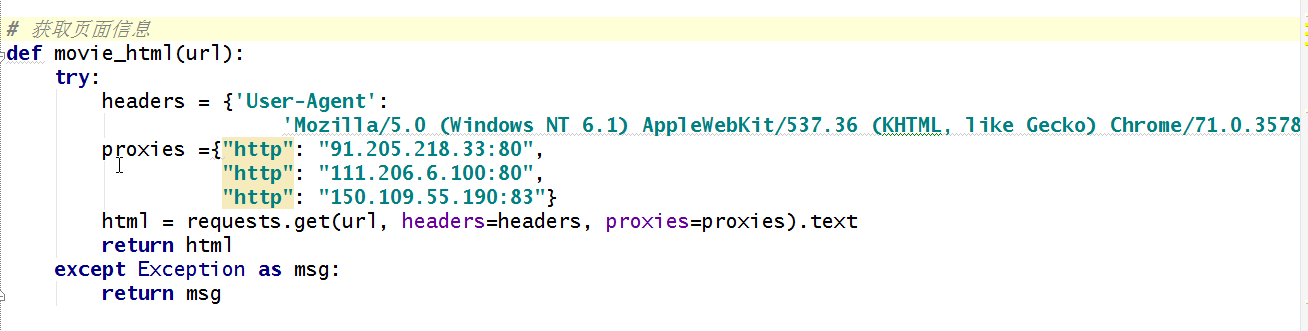
1、获取页面信息
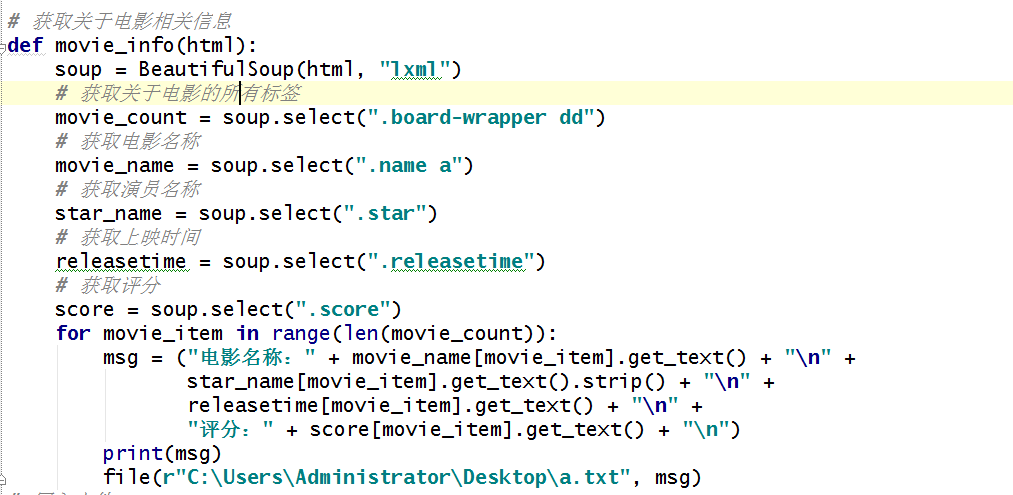
2、使用BeautifulSoup解析页面,获取相关信息
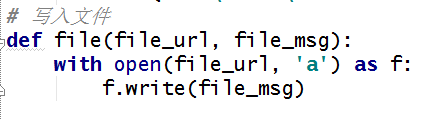
3、写入本地文件
4、获取其余页面

三、全部代码
from bs4 import BeautifulSoup
import requests
import time
获取页面信息
def movie_html(url):
try:
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
proxies ={"http": "91.205.218.33:80",
"http": "111.206.6.100:80",
"http": "150.109.55.190:83"}
html = requests.get(url, headers=headers, proxies=proxies).text
return html
except Exception as msg:
return msg
获取关于电影相关信息
def movie_info(html):
soup = BeautifulSoup(html, "lxml")
# 获取关于电影的所有标签
movie_count = soup.select(".board-wrapper dd")
# 获取电影名称
movie_name = soup.select(".name a")
# 获取演员名称
star_name = soup.select(".star")
# 获取上映时间
releasetime = soup.select(".releasetime")
# 获取评分
score = soup.select(".score")
for movie_item in range(len(movie_count)):
msg = ("电影名称:" + movie_name[movie_item].get_text() + "\n" +
star_name[movie_item].get_text().strip() + "\n" +
releasetime[movie_item].get_text() + "\n" +
"评分:" + score[movie_item].get_text() + "\n")
print(msg)
file(r"C:\Users\Administrator\Desktop\a.txt", msg)
写入文件
def file(file_url, file_msg):
with open(file_url, 'a') as f:
f.write(file_msg)
获取其余页面
def movie(offset):
url = "https://maoyan.com/board/4?offset={0}".format(offset)
html = movie_html(url)
movie_msg = movie_info(html)
return movie_msg
if name == 'main':
for i in range(10):
movie(i*10)
time.sleep(1)
欢迎来到testingpai.com!
注册 关于