聊一聊XPath表达式的小技巧
--- 柠檬班Jack导师
有同学问到 UI自动化关于XPath定位稳定性的问题,众所周知,找到了页面的元素,UI自动测试即完成了一半。那么写出稳定的XPath表达式就显得尤为重要了。所谓稳定性,即通过XPath定位出的元素运用在UI自动化脚本中:**能保证脚本健壮,****.**避免因为前端版本的迭代,隔三差五的修改元素定位表达式。
掌握了XPath基础语法的同学千万不要因为能唯一定位到页面中元素而沾沾自喜,指定页面中的一个元素,能唯一定位到的XPath定位表达式写法并不唯一,而这些XPath表达式的质量确高低不一,如何判断写出一个高质量的XPath表达式来用于UI自动化,就是本篇要讨论的主题。😀 😀
注:此处说的避免修改不是不改,而是少改。
废话不多说,请看分析:
1.杜绝使用绝对路径的XPath表达式
所谓绝对路径,即使用第一个标签作为根节点按照标签层级关系,一路找到所需定位的元素。
例如:访问连接:http://www.lemonban.com/front/articlelist/article/0,找到下图元素。
绝对定位
/html/body/div[1]/div[3]/div/div/section/section[2]/div[1]/section/article[1]/ul/li[10]/h3/a
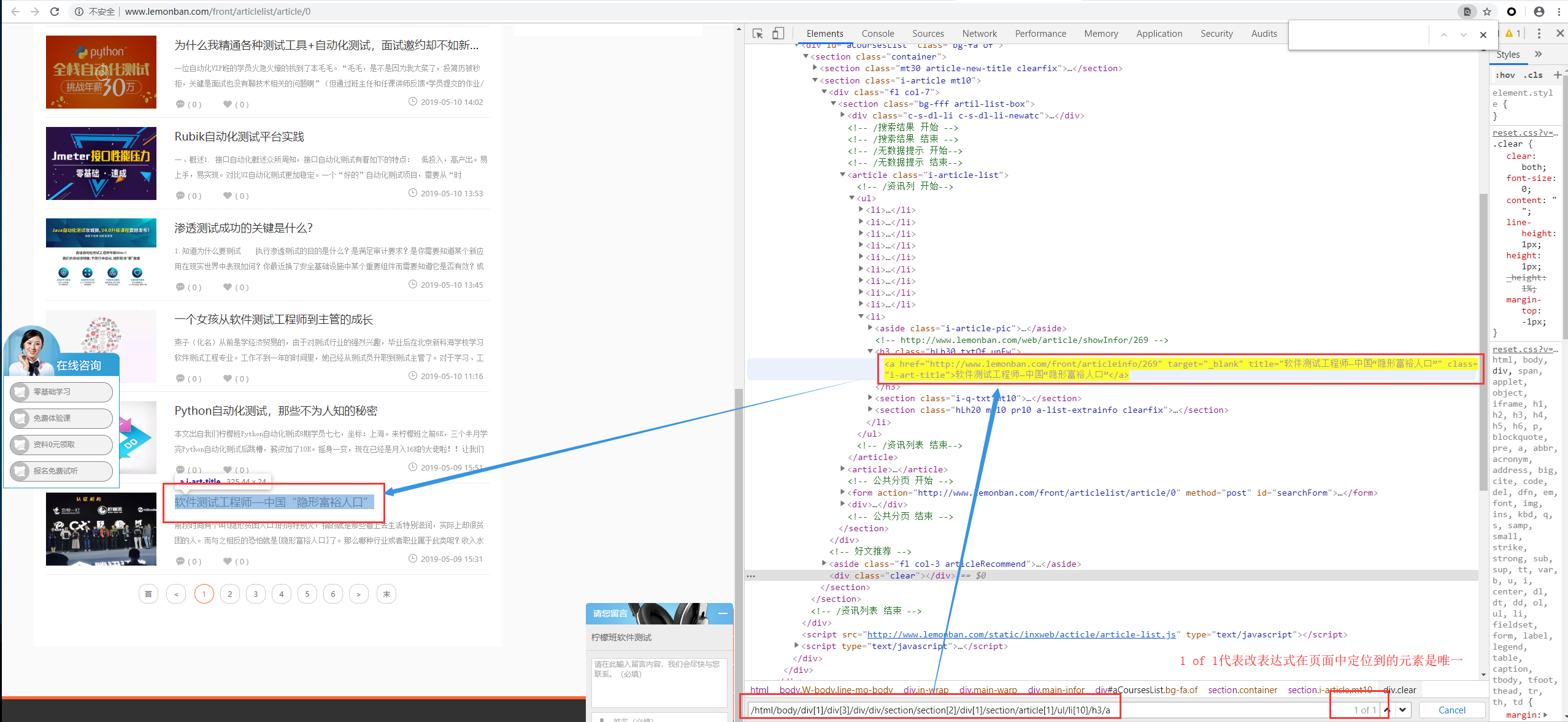
显然,绝对定位的写法是可以唯一定位到页面的任何元素的。
不过请同学们仔细看这个表示式:
/html/body/div[1]/div[3]/div/div/section/section[2]/div[1]/section/article[1]/ul/li[10]/h3/a
特点:
-
表达式从根节点
<html>标签开始按照层级关系唯一找到了需要定位的元素 -
表达式中充斥了大量的div标签
-
路径链式关系太长
有一定前端基础的同学不难知道,类似于
<div>, <span>,<li>等布局元素,在页面中的出现的占比几乎占了90%,那么问题来了,前端需求层出不穷,今天上个活动,明天上个广告,每一个版本的迭代,必然会大量增加或者改动<div>,<span>这类布局元素。这样一来在我们上面的绝对定位表达式是不是显得尤其的不稳定。
所以得出结论:使用XPath元素的绝对定位的方法悔恨终生。
那么,为了避免“前端工程师手一抖,自动化测试忙一宿”的尴尬,这里引出绝对定位方式,关于绝对定位方式的基本语法,这里不做赘述,请参考***文章***
2.相对定位表达式的惯用写法
想必通过简单练习XPath相对定位语法的你,已经可以写出能唯一定位到元素的相对定位表达式了。例如还是上面的例子,你肯定闭眼写出了以下相对定位表达式:
//article//h3//a[@title="软件测试工程师—中国“隐形富裕人口”"]
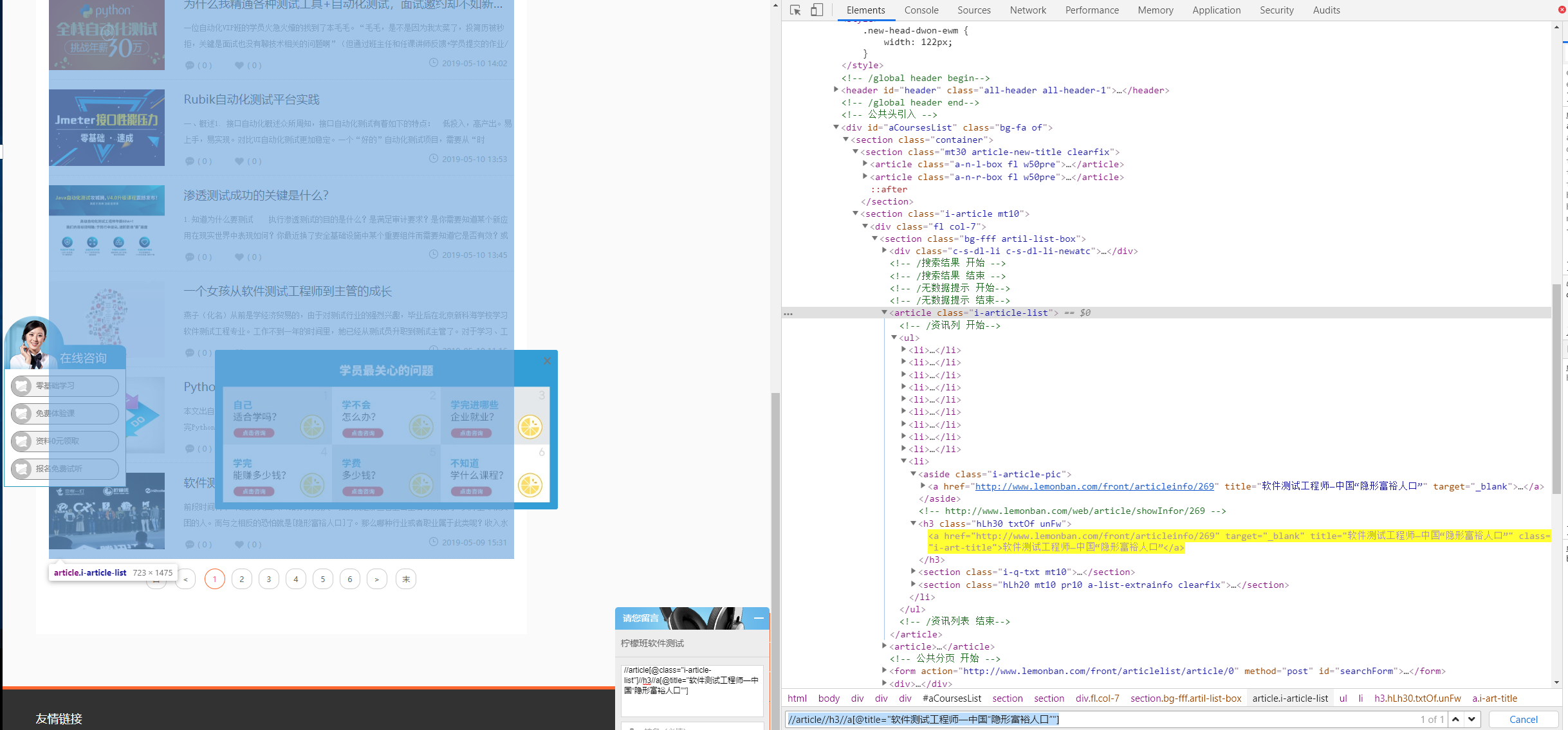
2.//*[@id="aCoursesList"]//h3//a[text()="软件测试工程师—中国“隐形富裕人口”"]

不难看出,这两种相对定位表达式。都是找到了一个有代表性的父级元素,然后通过不易变动的层级关系标签找到了需要定位的元素.
这里注意两个点:
-
有代表性的父级元素,类似于
<article>标签或者有id值的父级元素 -
不易变动的链式元素,这里的
<h3>是文章3级标题的一个元素
看到这里,你的XPath定位又比之前进步了一大截,下面我们来说说,进一步的优化表达式:
3.使用更少的层级定位
XPath表达式即是描述了元素之间的位置关系,通过链式语法找到元素,那么这个链就要做到越短越好,避免一个环节元素出问题而影响到表达式的输出。再看例子,打开以下页面:> http://www.lemonban.com/front/teacherlist
我们要在众多老师中找到小简,按照上面的套路,你可能会写出:
1.//*[@id="aCoursesList"]//li//div//a[text()="小简"]
这样的表达式。
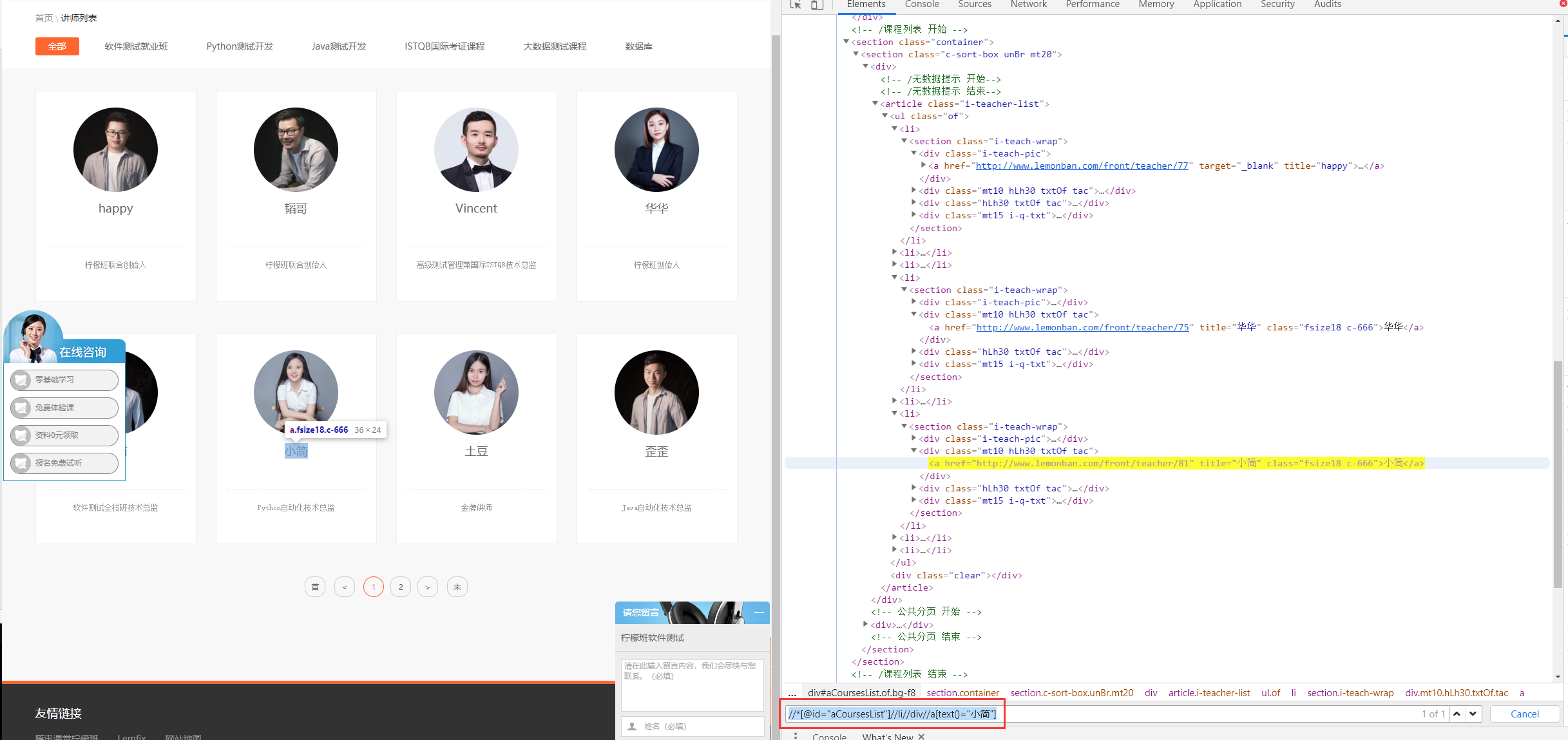
很显然,这个表达式通过4个层级关系找到了小简老师,但是分析一下,其中一部分链式是不是显得多余,请看表达式:
2.//*[@id="aCoursesList"]//a[text()="小简"]
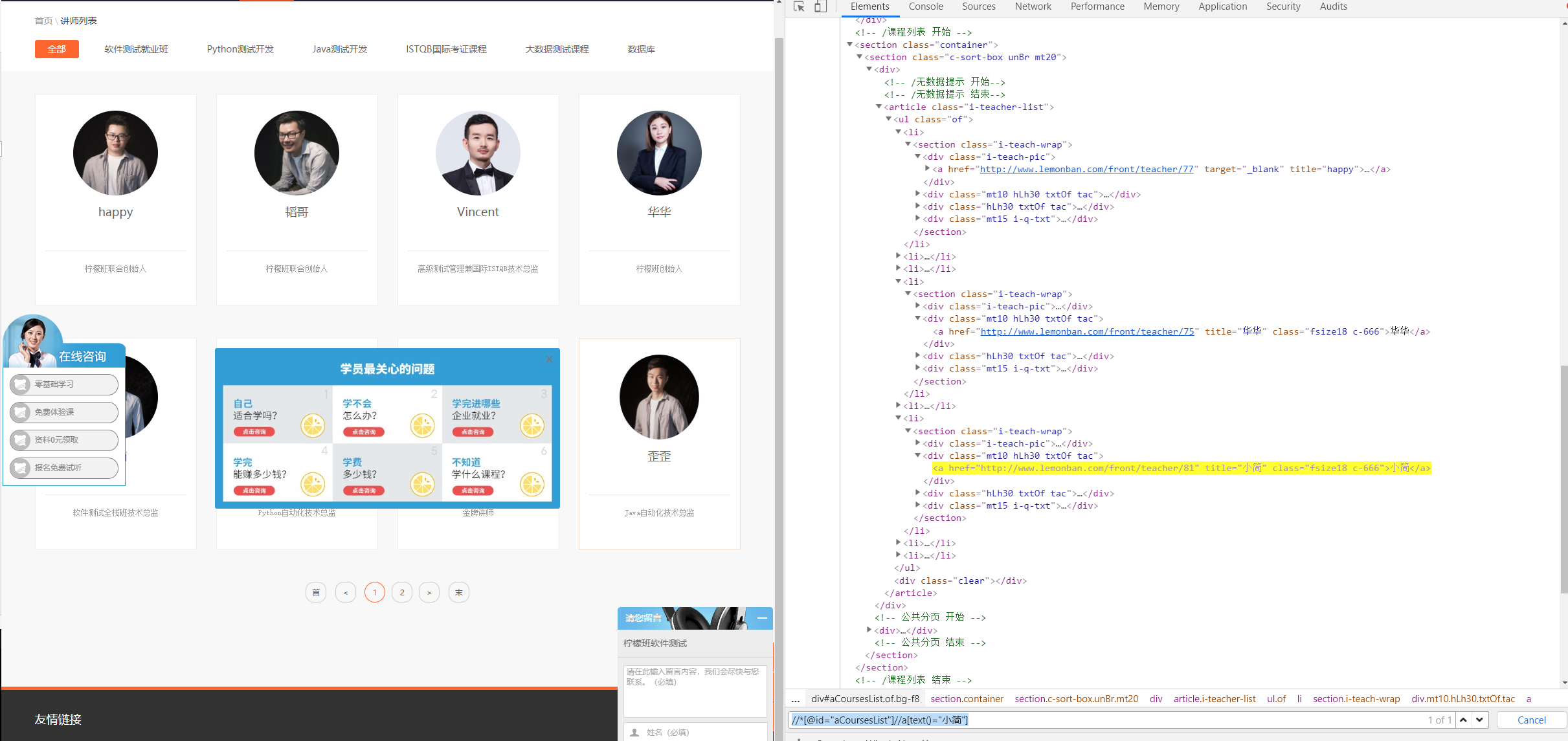
去掉了链式中的div,li同样可以找到小简老师;
再看表达式:
3.//a[text()="小简"]
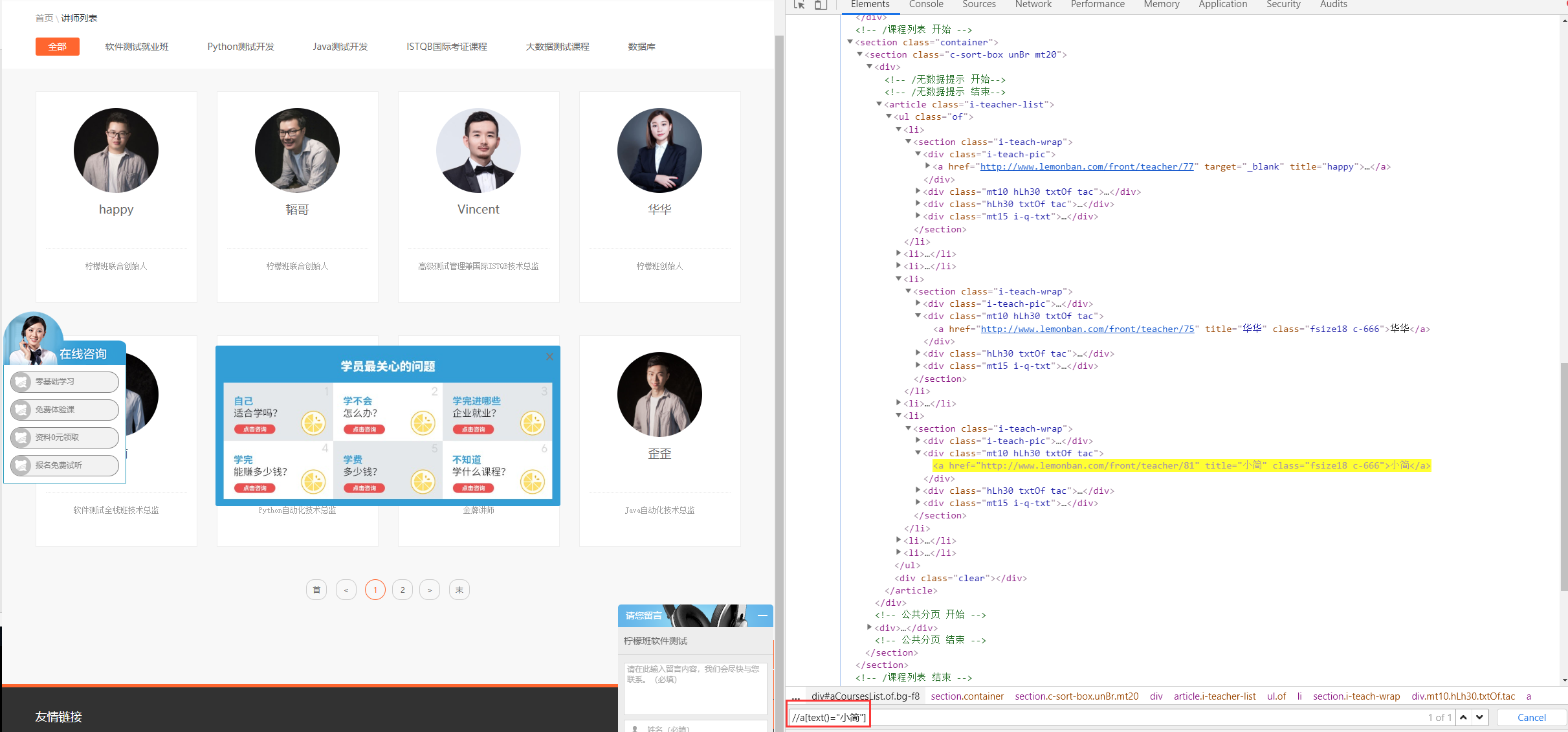
去掉了父级元素是不是也找到了小简。这时候这个链式只有一个标签,就是最优解.
得出结论:相对定位中的表达式链式关系越少越好。我们在写XPath表达式的时候,要从简到繁,最简单的方式定位不到的时候,再去思考找到合适父级或是轴定位找兄弟级。
4.善用 组元素
组元素,即通过一个表达式可以定位出一组元素。有些时候,并不是能唯一定位到元素的表达式就是好的表达式,根据业务需求,善于利用一组元素,也可以大大减少我们元素维护工作,看例子:
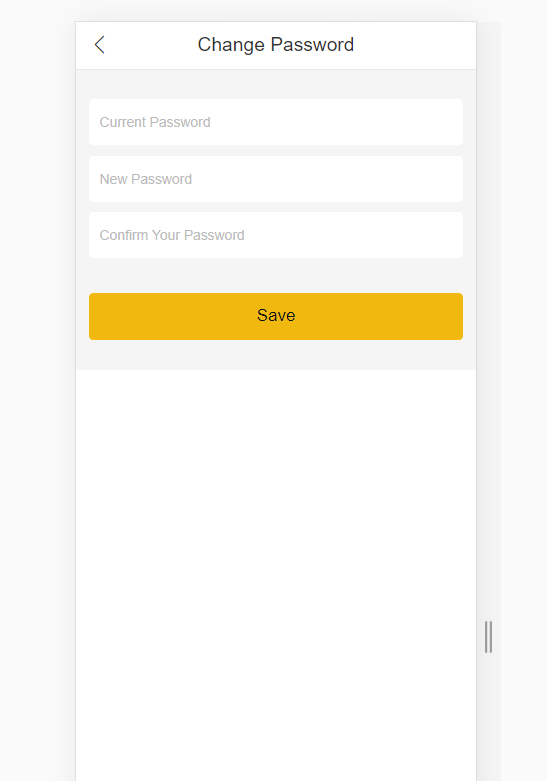
如图是一个修改密码的页面,如果按照常规套路,唯一定位出三个输入框的元素,表达式如下:
//input[@placeholder="Current Password"]
//input[@placeholder="New Password"]
//input[@placeholder="Confirm Your Password"]
那么请同学们仔细观察这个页面,主要操作元素都是输入框,我们何不利用表达式定位出一组元素,再通过取index的方式去操作元素呢?那么元素表达式写成一个//input即可,这样写,随便迭代时属性值怎么变化,input标签总归不会变吧,一个input标签能用到离职都不用维护。
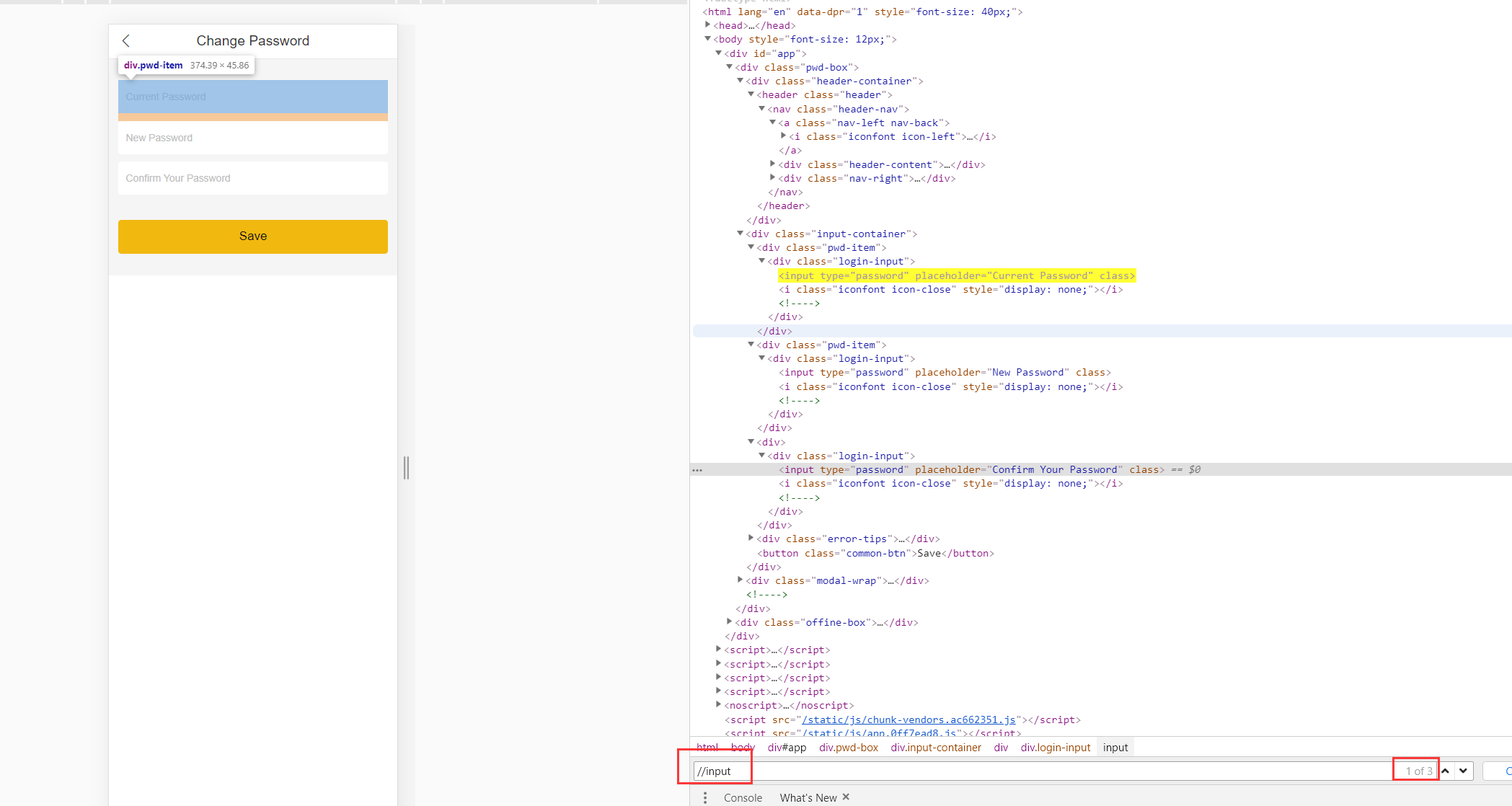
得出结论:根据需求,恰当的时候使用组选择器表达式更容易维护
5.多用contains
contains写法://标签名[contains(@属性名,“部分属性值”)]
意思是:找出该标签下对应属性名包含 部分值的元素
例如://a[contains(text(),"Python")]就是说找到一个a标签,它的文本值要包含“Python”
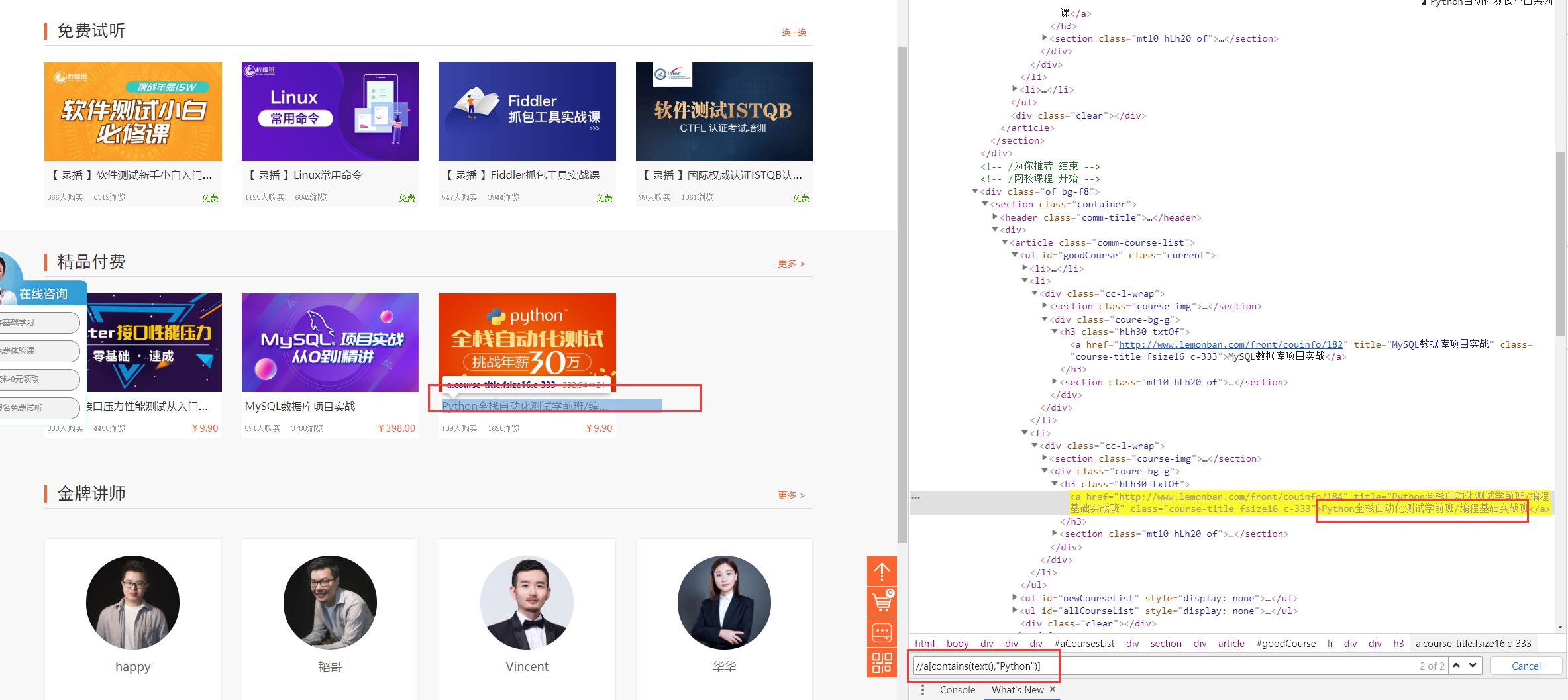
这种标签的用法一般在哪里呢?
列举一二:
- 一般前端写一个元素时,会给这个元素附一个通俗易懂的id值或者name或者value值,如图:
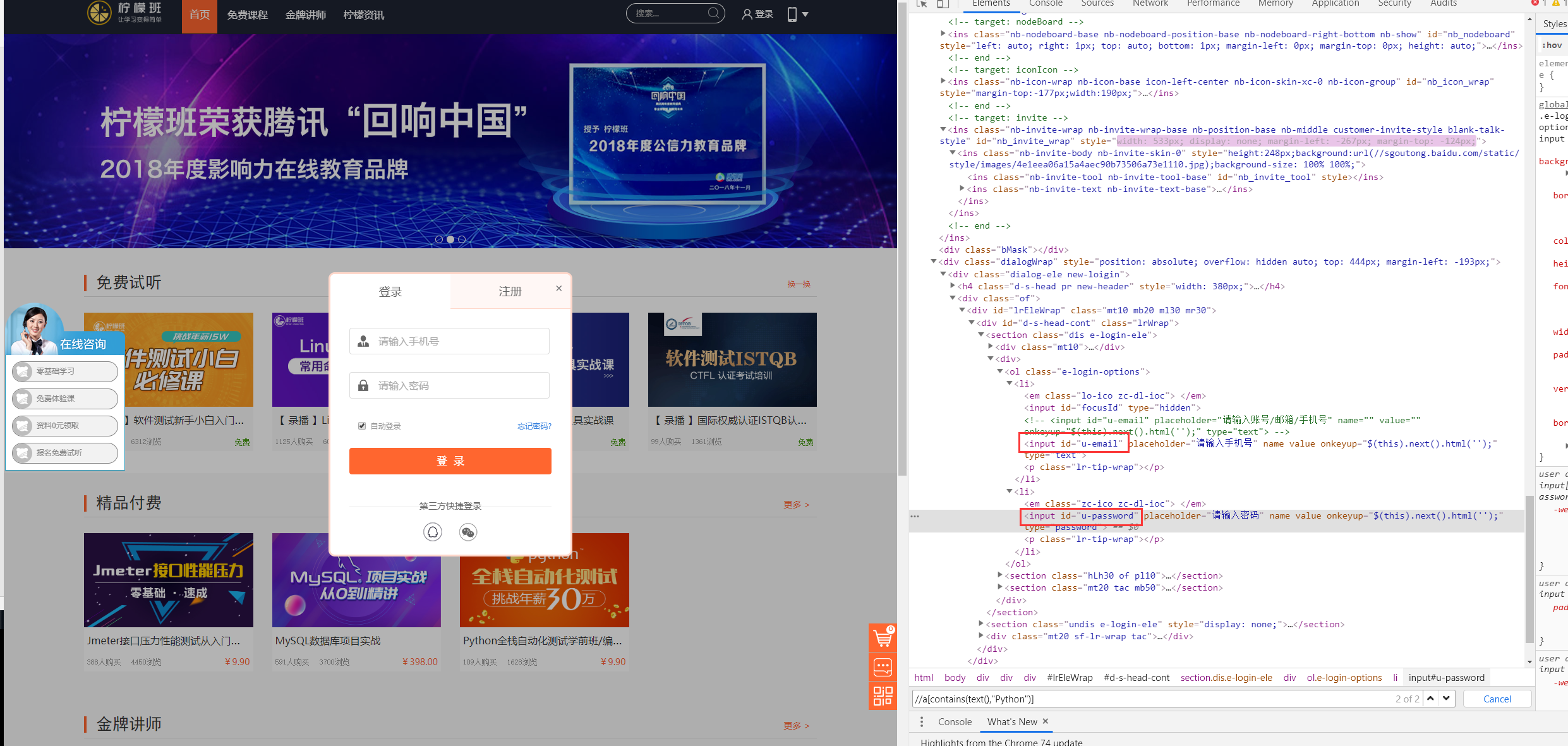
登录输入框,id=”u-email”,id=”u-password”;这里的email和password就是通俗易懂的吧,那么XPath你可能这样写:
//*[@id="u-email"]
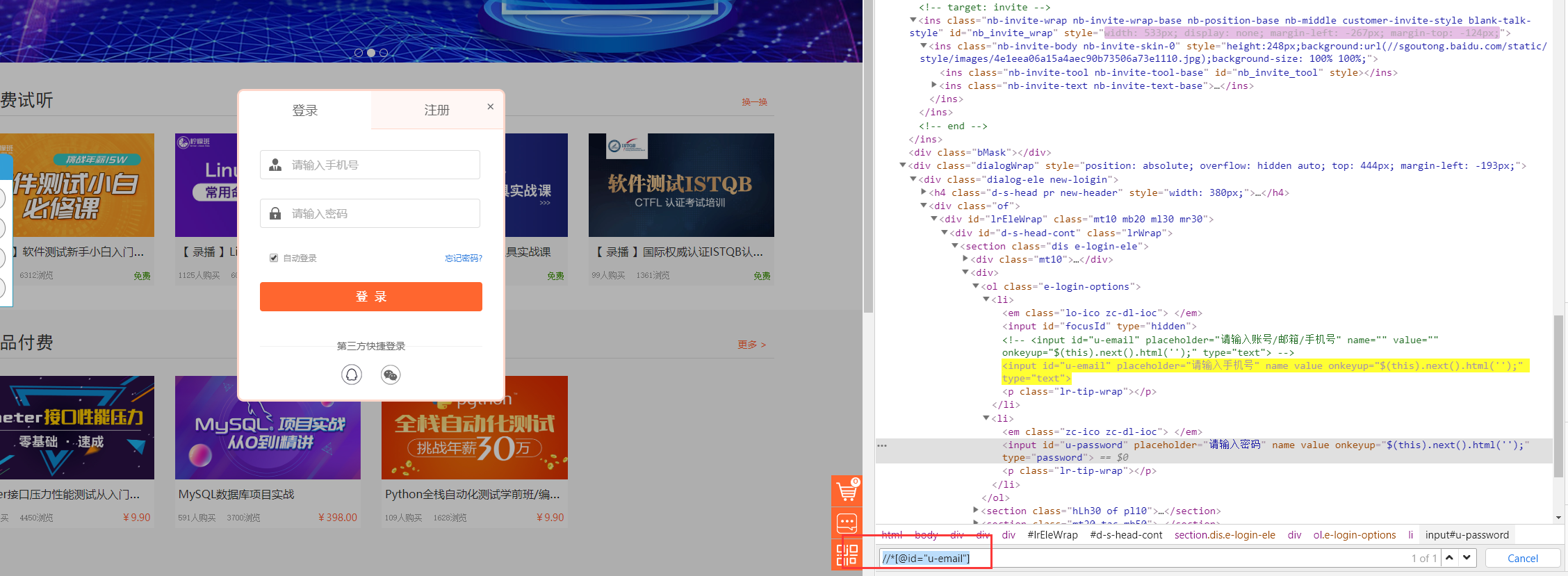
当然,学会了contains语法也可以这样写:
//*[contains(@id,"email")]

这两个写法哪一个好呢?
我们想一想,今天前端用了u-email,明天也有可能使用x-email,后天还有可以直接是email,如果采取第一种写法,那么恭喜你,陷入了改表达式的死循环。
如果采取了第二个写法,这点时间可以去冲杯咖啡了。
另外,有一些易变动的属性值,例如是后端抛给前端的属性值,中间含有一串按需变动的数字,这时候用这种contains的语法也是屡试不爽。
得出结论:找准了关键字,使用模糊匹配能匹配到就是用模糊匹配。可大大减少维护成本。
6.使用模糊匹配 配合组元素
看例子:找出所有站内的文章的链接
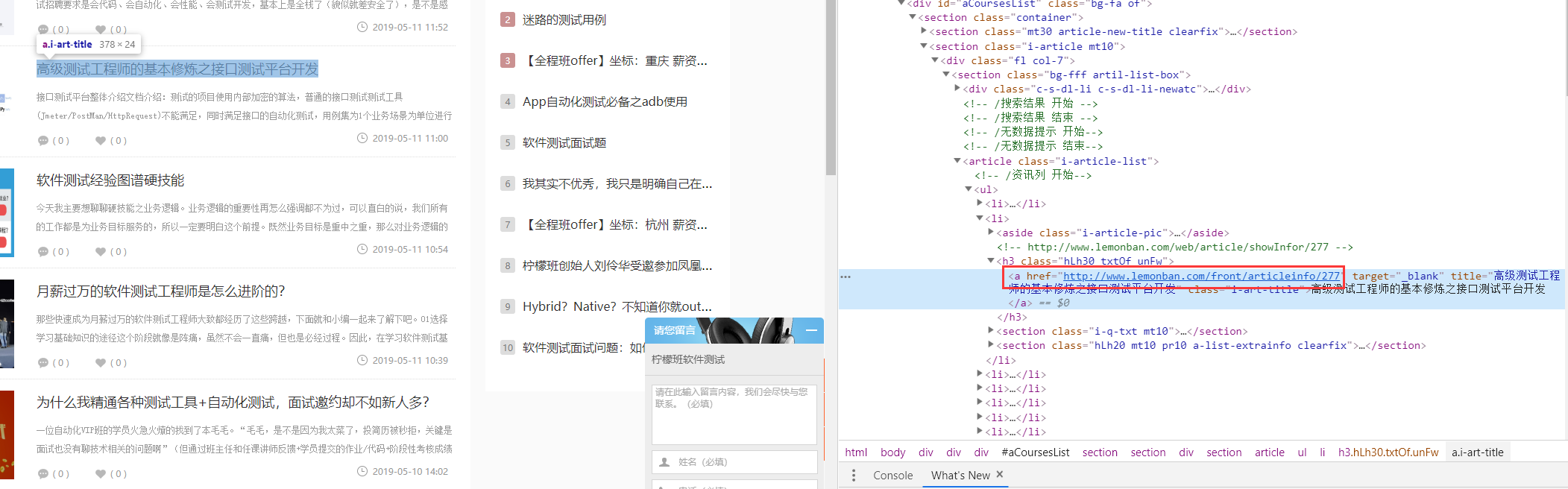
看到这个文章的连接:http://www.lemonban.com/front/articleinfo/277
分析一下需求 :站内:lemonban;文章:articleinfo
第一步找出链接:133个
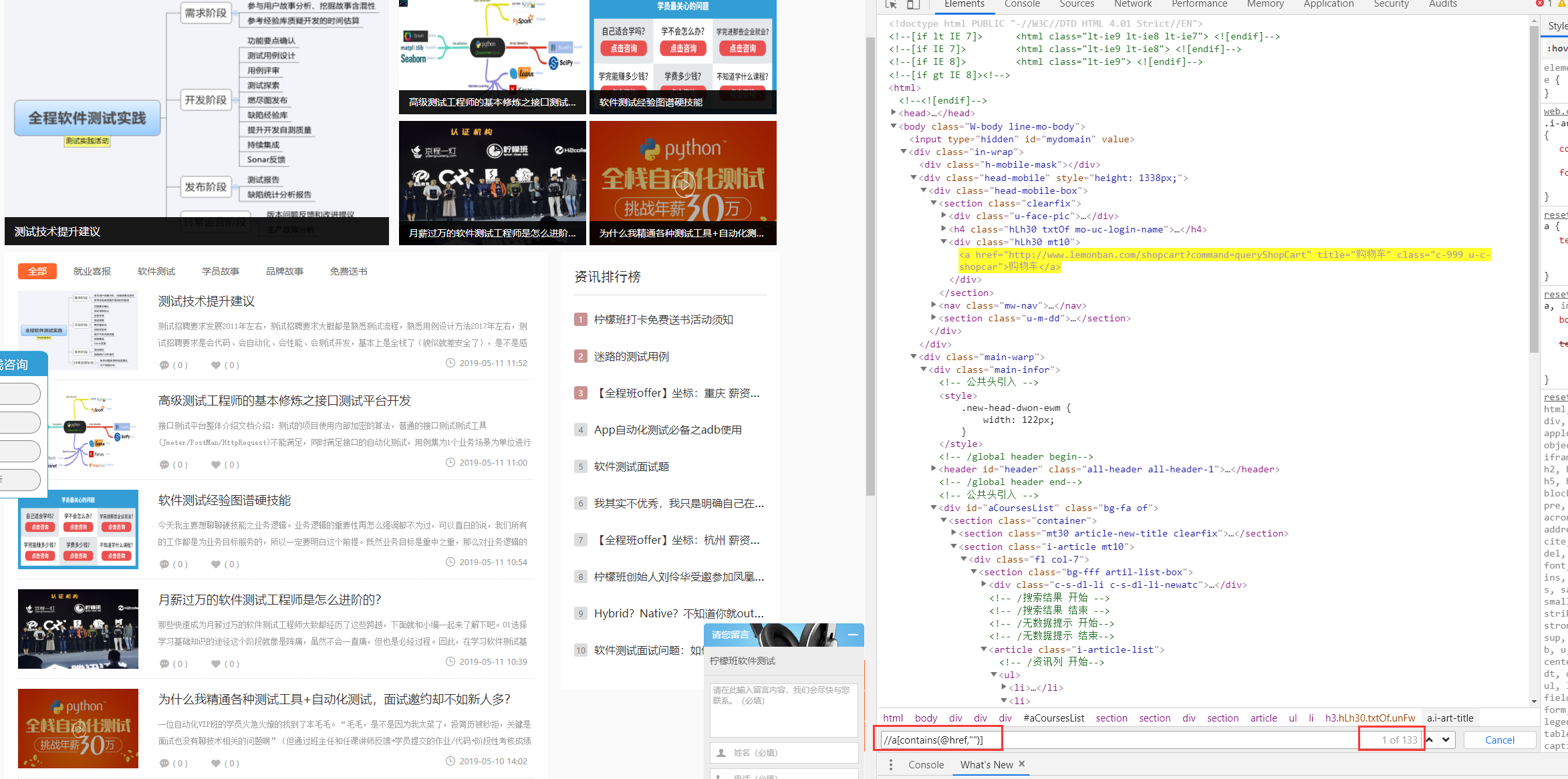
第二步找出站内:71个
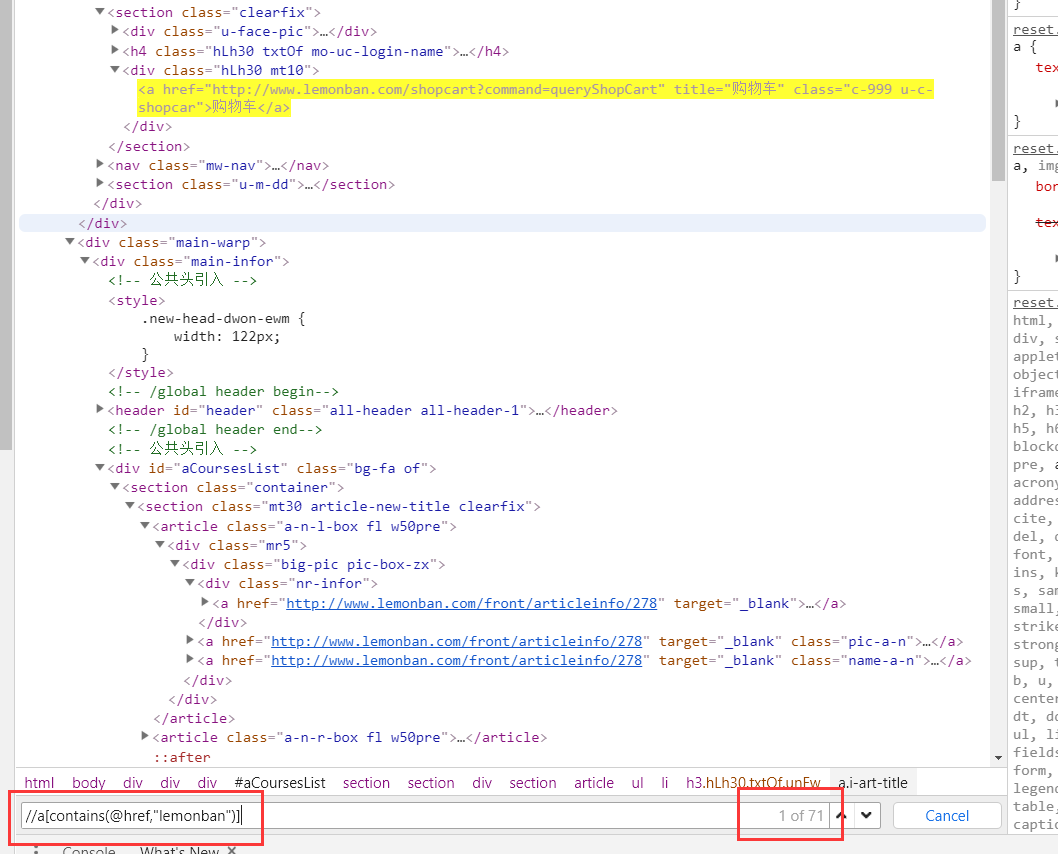
第三步找出站内的文章:55个
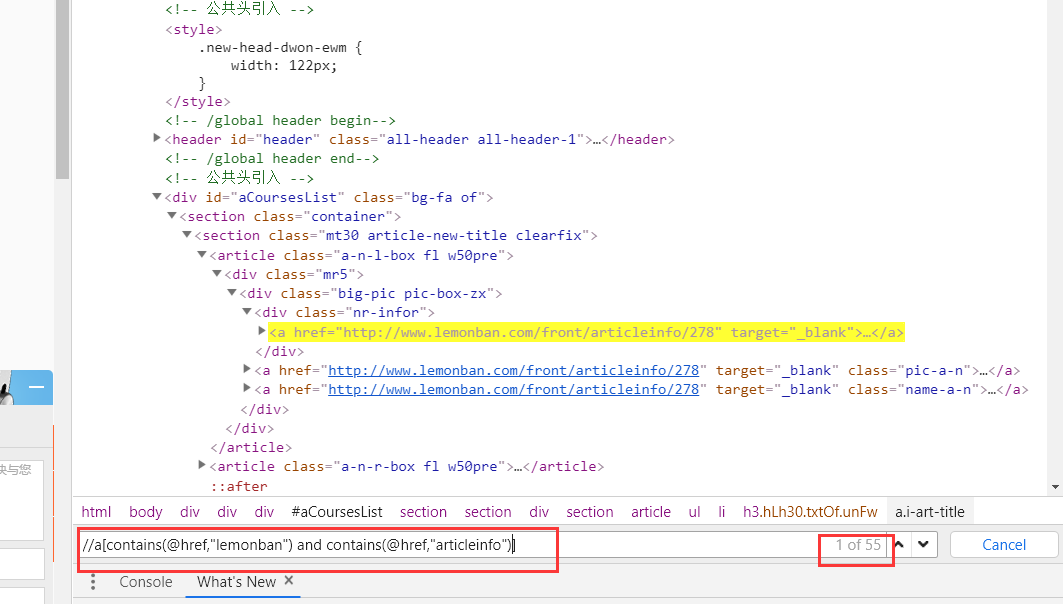
看到了contains的强大了吗?
得出结论:.根据需求场景,contains配合 组选表达式更容易完成需求。
拿到一个前端页面的时候,首先要分析页面结构,分为哪些模块,按照页面结构使用上面的技巧编写XPath表达式往往需要维护的成本更小,相信同学们通过一定的实践,一定会深有感悟。
有机会再聊点别的。

欢迎来到testingpai.com!
注册 关于