本人小白 最近在尝试学习Python 开篇记录 只为交流 相互学习O(∩_∩)O~~
Selenium,化学元素硒的英文示意,对于软件测试来书,则是一个主要用于Web应用程序自动化测试的工具集合;
之前有这个计划来学习和使用自动化测试到项目中去,以满足公司需求,所以闲时就买了本书,内容较简洁,实践学习中;
前言:
旨在学习使用Python语言调用Selenium WebDriver接口进行自动化测试;
作为一名小白,我们先来看看所需的入门知识和信息;
1.Selenium WebDriver:业界通用的测试框架,不仅是web测试的标准,同时在移动测试领域也是底层的核心驱动框架;
2.Python作为动态语言,其优点多多,前一阶段用了一段时间简单熟悉了下Python语法,感兴趣的同学可移步查看;
Selenium包括一系列的工具组件:
1.Selenium IDE:是嵌入到FireFox浏览器的插件,用于在Firefox上录制和回放Selenium脚本;
虽然只能在Firefox下使用,但它能将录制好的脚本转换成各种Selenium WebDriver支持的程序语言,进而扩展到更广泛的浏览器类型;
2.Selenium WebDriver:可支持多种语言,用于操作浏览器的一套API;支持各类型浏览器,跨操作系统;
WebDriver为诸多语言提供完备的,用于实现web自动化测试的第三方库;
3.Selenium Standalone Server:包括Selenium Grid、远程控制、分布式部署等,均可实现Selenium脚本的高效执行与拓展;
利用Grid使得自动化测试可以并行运行,甚至在跨平台、异构的环境中运行,包括主流的移动端环境,如Android、iOS;
学习准备:Python语言及语法,Web前段知识(这个了解的很少/(ㄒoㄒ)/~~),至于一些前期准备和环境配置,我们稍后来实践;
一、基于Python的Selenium WebDriver入门
Selenium可以自动操纵浏览器来做很多,如模拟与浏览器的交互,而且支持到多数主流浏览器;
我们首先需要选择一门语言来编写自动化脚本,而这门语言需要有Selenium client library支持;我们选择Python;
1.1 安装Python和Selenium包
安装Python:安装不同平台的Python可以在http://python.org/download/
安装Selenium:使用pip工具https://pip.pypa.io/en/latest/ 按照文档,需要先执行脚本get-pip.py 下载执行即可;
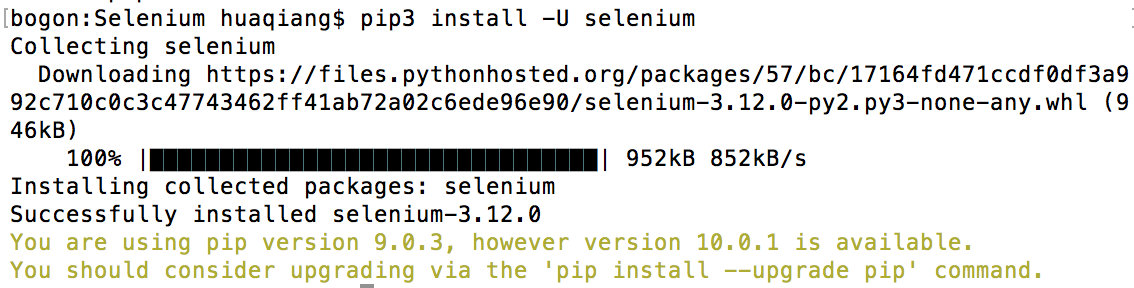
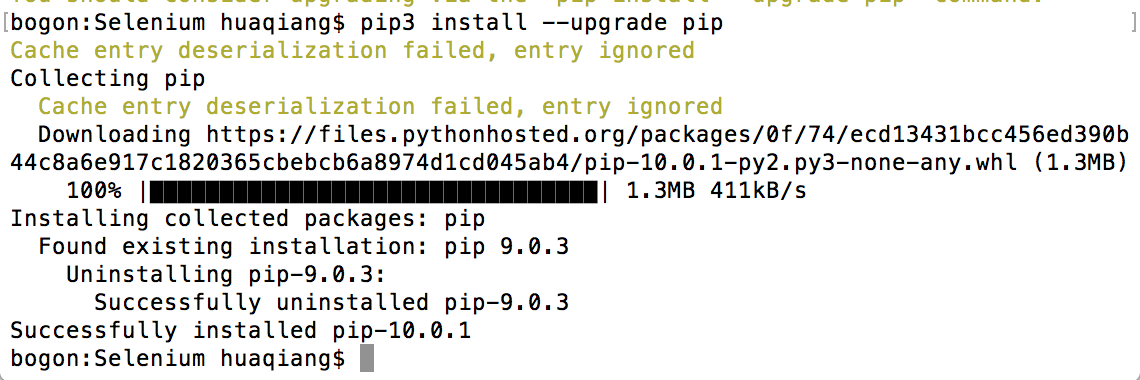
之后执行终端命令:pip3 install -U selenium
来安装Selenium WebDriver client library;-U参数会将已经安装的旧版更新至新版;可查阅官方文档;
1.2 PyCharm设置
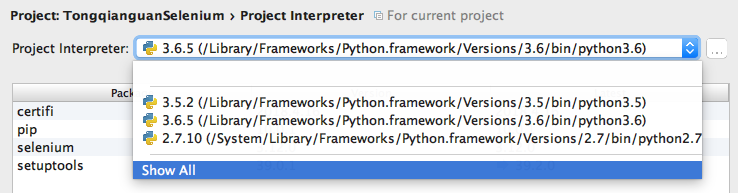
PyCharm有两个版本:社区版和专业版,社区版是免费的,可以下载使用;
在使用PyCharm时,需要配置Python的解释器,我们选择支持selenium的Python版本解释器;
1.3 Selenium WebDriver基于Python的实例脚本
我们尝试创建一个引用Selenium WebDriver Client library的Python脚本,使用Selenium WebDriver提供的类和方法模拟用户与浏览器的交互;
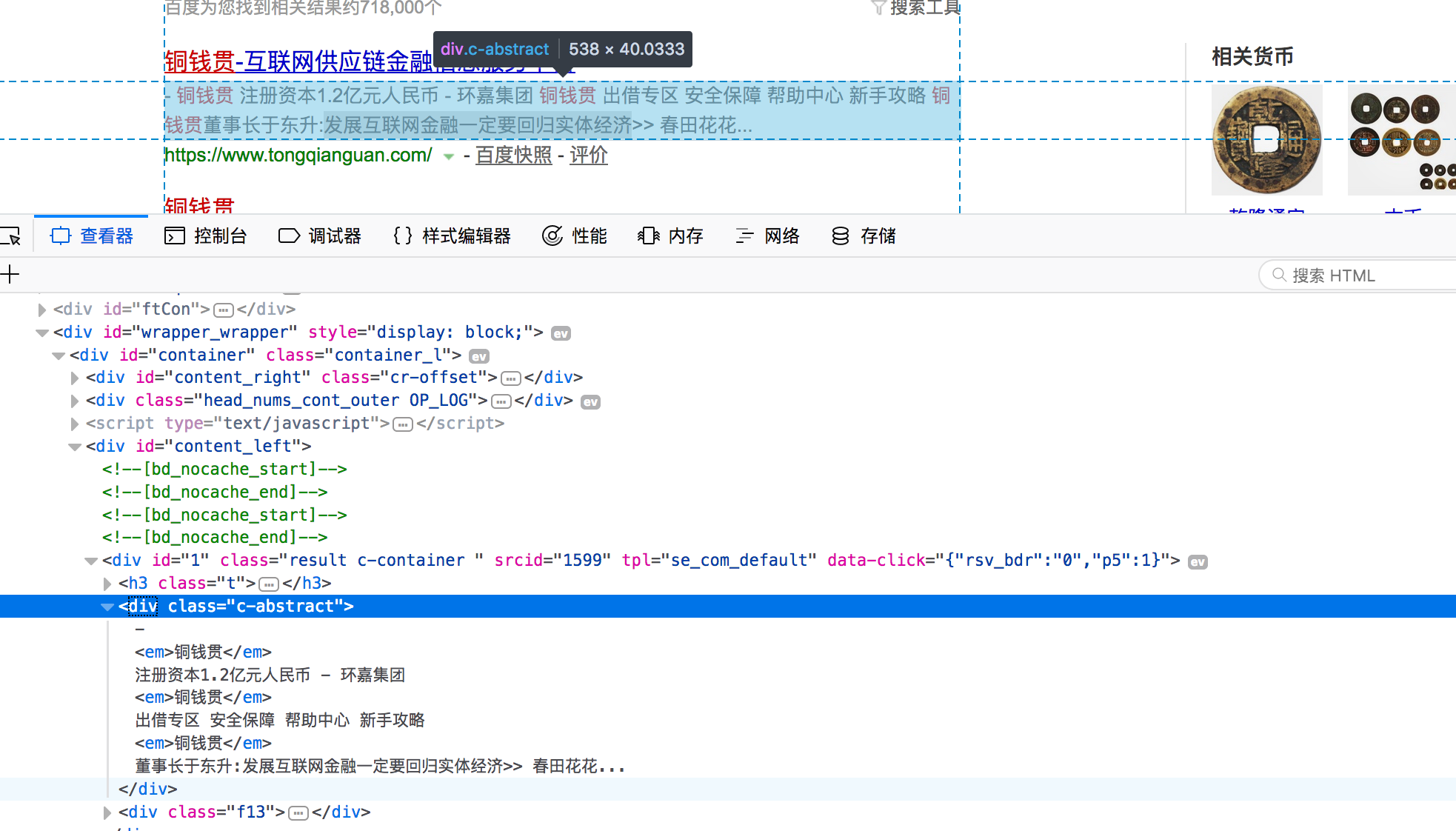
我们尝试使用百度搜索来实践这个脚本:搜索“铜钱贯”,并打印搜索记录的内容:
Python脚本编辑如下:(searchproducts.py)
# -*- coding:utf-8 -*- from selenium import webdriver # create a new Firefox session driver = webdriver.Firefox()driver.implicitly_wait(10)#设置超时时间driver.maximize_window()#窗口最大化显示 # navigate to the application home page driver.get("http://www.baidu.com/") # get the search textbox search_field = driver.find_element_by_id("kw")#找到输入框search_field.clear()#清空当前输入内容 # enter search keyword and submit search_field.send_keys("铜钱贯")#重新这是搜索关键字search_field.submit()#提交进行搜索 # get all the anchor elements which have product names displayed# currently on result page using find_ elements_ by_ xpath method products = driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") # get the number of anchor elements found print ("Found " + str(len(products)) + "products:") # iterate through each anchor element and print the text that is# name of the product for product in products: print (product.text) # close the browser window # driver.quit()
接下来我们运行脚本:
这里可能会遇到这样一个错误:

相应的解决办法如下:(geckodriver)

下载符合系统的文件,解压之后进行移动:

值得说明的是geckodriver是针对Firefox的,和我们一会要说的ChromeDriver和InternetExplorerDriver类似;
问题解决了我们继续;
我们会看到一个Firefox浏览器窗口访问百度搜索页,同时进行关键字的搜索,顺利的话,最终会在控制台打印输出上图中标签标记的记录内容;(部分输出内容如下)
语句的分析示意,简单作了注释,还有很多功能需要不断的去学习和使用;
- 从Selenium包导入WebDriver才能使用Selenium WebDriver的方法;
- 选用一个浏览器驱动实例,会提供一个几口去调用Selenium命令来跟浏览器交互;
- 设置30s隐式等待时间来定义Selenium执行步骤的超时时间;
- 调用driver.get()方法访问该应用程序,方法调用后,WebDriver会等待,一直到页面加载完成才继续执行脚本;
- Selenium WebDriver提供多种方法来定位和操作这些元素,例如设置值,单击按钮,在下拉组件中选择选项等;这里使用find_element_by_id来定位搜索输入框;这个方法——会返回第一个id属性值与输入参数匹配的元素;(HTML元素是用标签和属性定义的)
- 通过send_keys()方法输入新的特定值,调用submit()提交搜索请求;
- 加载搜索结果页面,我们读取结果列表的内容并打印输出;通过find_elements_by_xpath获取路径满足class='c-abstract'的所有div标签,它将返回多于一个的元素列表;
- 最后我们打印,获取到的标签的文本内容;在脚本的最后,我们可以使用driver.quit()来关闭浏览器;
这个例子向我们展示了如何使用Selenium WebDriver和Python配合来创建一个简单的自动化脚本;(眼下这个脚本还没有测试什么)
Selenium.webdriver模块实现了Selenium所支持的各种浏览器驱动程序,包括Firefox、Chrome、IE、Safari等;
此外,RemoteWebDriver则是用于远程机器进行浏览器测试的;
对于IE浏览器:
需要下载并安装InternetExplorerDriver,是一个独立的服务,他实现了WebDriver的协议,使得WebDriver可以可以和IE浏览器交互;
下载解压放到存储脚本的目录中即可;(IE7以上版本,每个区域的保护模式需要设置相同的值)
IE下的脚本需要我们修改才能使用;
对于Chrome浏览器:
需要下载ChromeDriver服务,该服务支持多系统,有Chromium team开发维护;
下载完成后复制到脚本的目录中;
修改脚本使其支持Chrome浏览器;
修改脚本的方式这是通过os模块,通过os.path.dirname(file) + "\chromedriver"得到的执行文件路径,作为webdriver.Chrome(xxx)启动驱动器实例的参数,IE亦如此;(Windows下需要加上可执行文件的后缀,如.exe)
接下来,我们尝试通过Selenium WebDriver使用unittest库来创建自动化单元测试,并学习如何创建并运行一组测试脚本;
二、使用unittest编写单元测试
首先我们来回顾一下Selenium WebDriver,它是一个浏览器自动化测试的API集合;提供了很多与浏览器交互的特性;
但是,仅仅使用Selenium WebDriver,我们还有一些无法实现的:比如 实现执行测试前置条件、测试后置条件,比对预期结果和实际结果,检查程序的状态,生成测试报告,创建数据驱动测试等功能;
那么,现在我们来看如何使用unittest来创建基于Python的Selenium WebDriver测试脚本;
2.1 什么是unittest
unittest单元测试框架:
一般也称为PyUnit,是从Java程序开发中广泛应用的JUnit启发而来的;我们可以使用unittest为任何项目创建全面的测试套件;
unittest使我们具备创建测试用例、测试套件、测试夹具的能力;
unittest组件:
- Test Fixture(测试夹具):
使用测试夹具,可以定义在单个或多个测试执行之前的准备工作和测试执行之后的清理工作;
- Test Case(测试用例):
unittest中执行测试的最小单元,通过验证unittest提供的assert方法来验证一组特定的操作和输入以后得到的响应;
unittest提供了一个名为TestCase的基础类,可以用来创建测试用例;
- Test Suit(测试套件):
一个测试套件是多个测试或测试用例的集合,是针对被测程序的对应的功能和模块创建的一组测试,一个测试套件内的测试用例将一起执行;
- Test Runner(测试执行器):
测试执行器负责测试执行调度并且生成测试结果给用户;
测试执行器可以使用图形界面、文本界面或者特定的返回值来展示测试执行结果;
- Test Report(测试报告):
测试报告展示所有执行用例的成功或者失败状态的汇总;包括失败的测试步骤的预期结果和实际结果,还有整体运行状况和运行时间的汇总;
2.2 使用unittest来写Selenium WebDriver测试
一般的测试可被拆分为3部分,即3A`s:
- Arrange:初始化前置条件,初始化被测试的对象,相关配置和依赖;
- Act:执行功能操作;
- Assert:用来校验实际结果与预期结果是否一致;
这是一种方法,我们接下来将应用此方法来为unittest创建测试;
2.3 用TestCase类来实现一个测试
我们将通过集成TestCase类并且 在测试类中为每一个测试添加测试方法来创建单个测试或者一组测试;
TestCase中的assert方法,最主要的任务是 调用assertEqual()来校验结果;assertTrue()来验证条件;assertRaises来验证预期的异常;
除了添加测试,还可以添加测试夹具,setUp()方法和tearDown()方法;
一个测试用例是从setUp()方法开始执行,因此可以在每个测试开始前执行一些初始化的任务;此方法无参数,也无返回值;
接着编写test方法,这些测试方法命名为test开头,这种命名约定通知test runner哪个方法代表测试方法;
值得注意的是:test runner能找到的每个测试方法,都会在执行测试方法之前先执行setUp()方法,这样有助于确保每个测试方法都能够依赖于相同的环境;
tearDown()方法.会在测试执行完成之后调用,用来清理所有的初始值;
最后就是运行测试:为了能通过命令行测试,我们可以在测试中添加对main方法的调用;我们将传递verbosity参数以便使详细的测试结果展示在控制台;
测试代码如下:
# -*- coding:utf-8 -*- import unittestfrom selenium import webdriver class SearchTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.implicitly_wait(15) self.driver.maximize_window() self.driver.get('http://www.baidu.com') def test_search_by_category(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(10, len(products)) def tearDown(self): self.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
如果测试通过则,浏览器最后会退出,如果出错的话,控制台则会打印出相关信息:

通过终端命令行运行的结果如下:

修改预期值,测试报错:
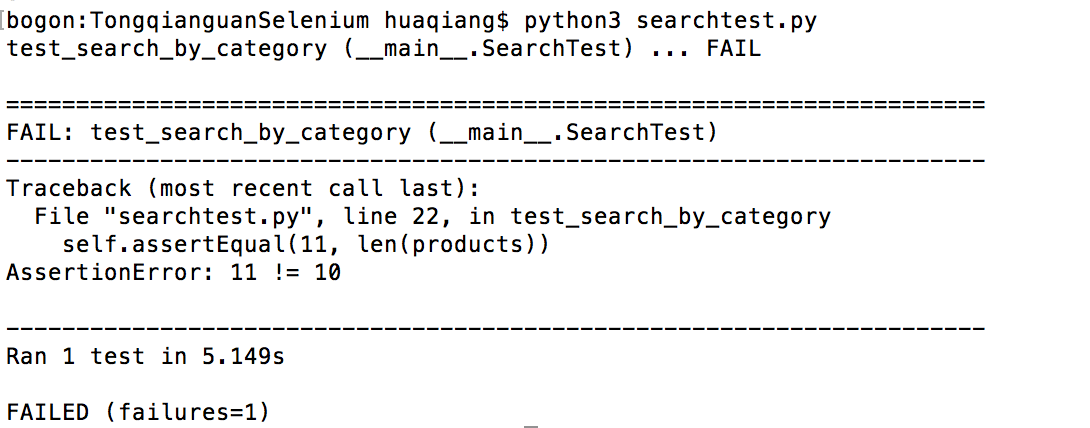
上一个实例,我们添加了一个测试,我们还可以用一组测试来构建一个测试类;这样有助于为一个特定功能创建一组更合乎逻辑的测试;
新的测试方法命名同样要以test开头;简单测试我们复制第一个示例中的测试,修改测试方法名;通过终端再次运行:(searchtest.py)
# -*- coding:utf-8 -*- import unittestfrom selenium import webdriver class SearchTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() self.driver.implicitly_wait(15) self.driver.maximize_window() self.driver.get('http://www.baidu.com') def test_search_by_category(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(11, len(products)) def test_search_by_category1(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(10, len(products)) def tearDown(self): self.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
运行结果如下:
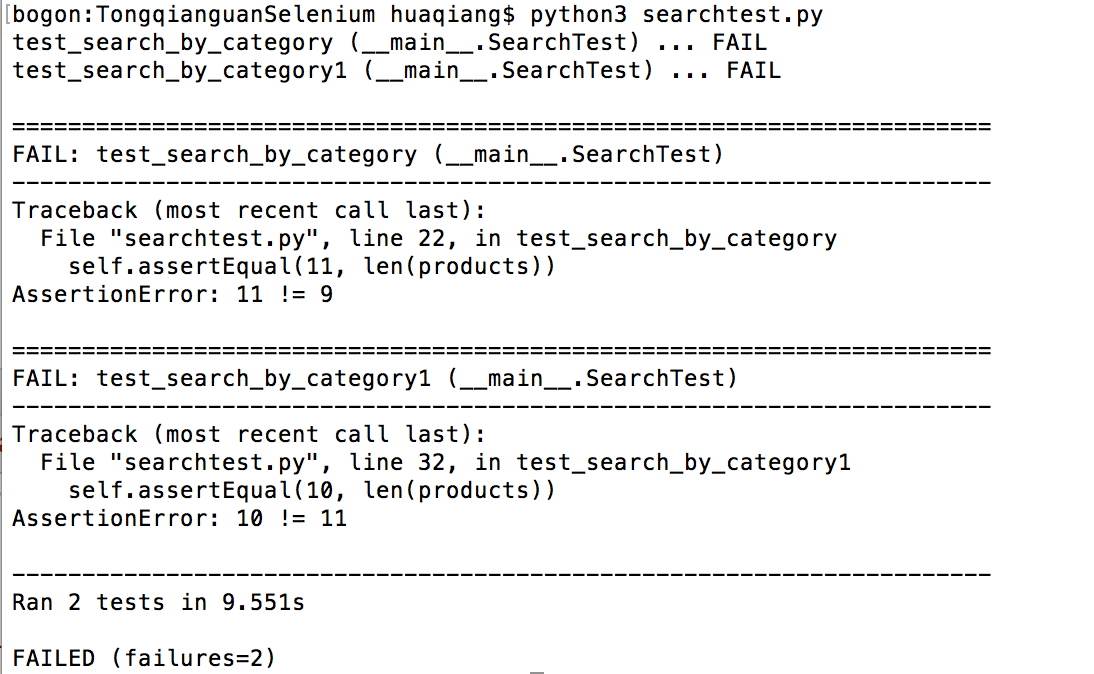
同时我们看到这这样的一个效果:两个Firefox的实例打开和关闭,对应setUp()和tearDown()方法执行的结果;
为了能让各个测试方法共用一个Firefox实例,我们可以创建类级别的setUp()和tearDown()方法:
- 通过setUpClass()方法和tearDownClass()方法及@classmethod标识来实现;
- 这两个方法使在类级别初始化数据,替代了方法级别的初始化;
我们修改测试脚本,并重新运行:(searchtest1.py)
# -*- coding:utf-8 -*- import unittestfrom selenium import webdriver class SearchTest(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Firefox() cls.driver.implicitly_wait(15) cls.driver.maximize_window() cls.driver.get('http://www.baidu.com') def test_search_by_category(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(11, len(products)) def test_search_by_category1(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(10, len(products)) @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
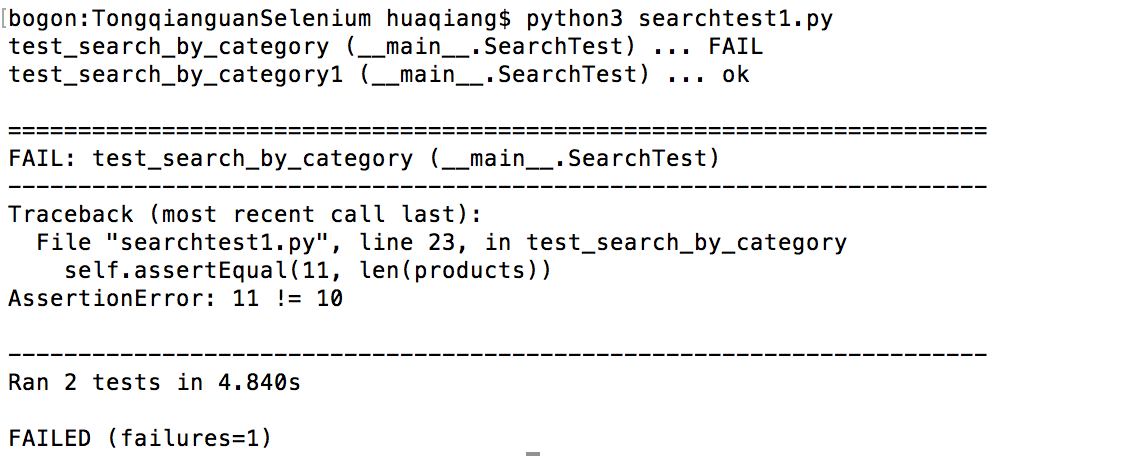
2.4 学习unittest提供的不同类型的assert方法
断言:unittest的TestCase类提供了很多实用的方法来校验预期结果和实际结果是否一致;
assertEqual(a, b [, msg]); assertNotEqual(a, b [, msg]);
assertTrue(x [, msg]); assertFalse(x [, msg]);
assertIsNot(a, b [, msg]);
assertRaises(exc, fun, *args, **kwds);
......
2.5 为一组测试创建TestSuite
应用unittest的TestSuites特性,可以将不同的测试组成一个逻辑组,然后设置统一的测试套件,并通过一个命令来执行;
具体通过TestSuites、TestLoader和TestRunner类来实现的;
我们将上一个脚本命名为searchtest1.py,同时我们新建一个脚本searchtest2.py如下:(searchtest2.py)
# -*- coding:utf-8 -*- import unittestfrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver.common.by import By class SearchTestHomePage(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Firefox() cls.driver.implicitly_wait(15) cls.driver.maximize_window() cls.driver.get('http://www.baidu.com') def test_search_by_category(self): self.assertTrue(self.is_element_present(By.ID, "kw")) def test_search_by_category1(self): self.search_field = self.driver.find_element_by_id("kw") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.search_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") self.assertEqual(10, len(products)) @classmethod def tearDownClass(cls): cls.driver.quit() def is_element_present(self, how, what): """""" try: self.driver.find_element(by=how, value=what) except NoSuchElementException as e: return False return True if __name__ == '__main__': unittest.main(verbosity=2)
接下来,我们来看看TestSuites特性是如何工作的:
新建另一个脚本如下:(searchtestsuites.py)
# -*- coding:utf-8 -*- import unittestfrom searchtest1 import SearchTestfrom searchtest2 import SearchTestHomePage search_test = unittest.TestLoader().loadTestsFromTestCase(SearchTest)search_test_homepage = unittest.TestLoader().loadTestsFromTestCase(SearchTestHomePage) smoke_tests = unittest.TestSuite([search_test, search_test_homepage]) unittest.TextTestRunner(verbosity=2).run(smoke_tests)
通过IDE我们运行这个脚本:
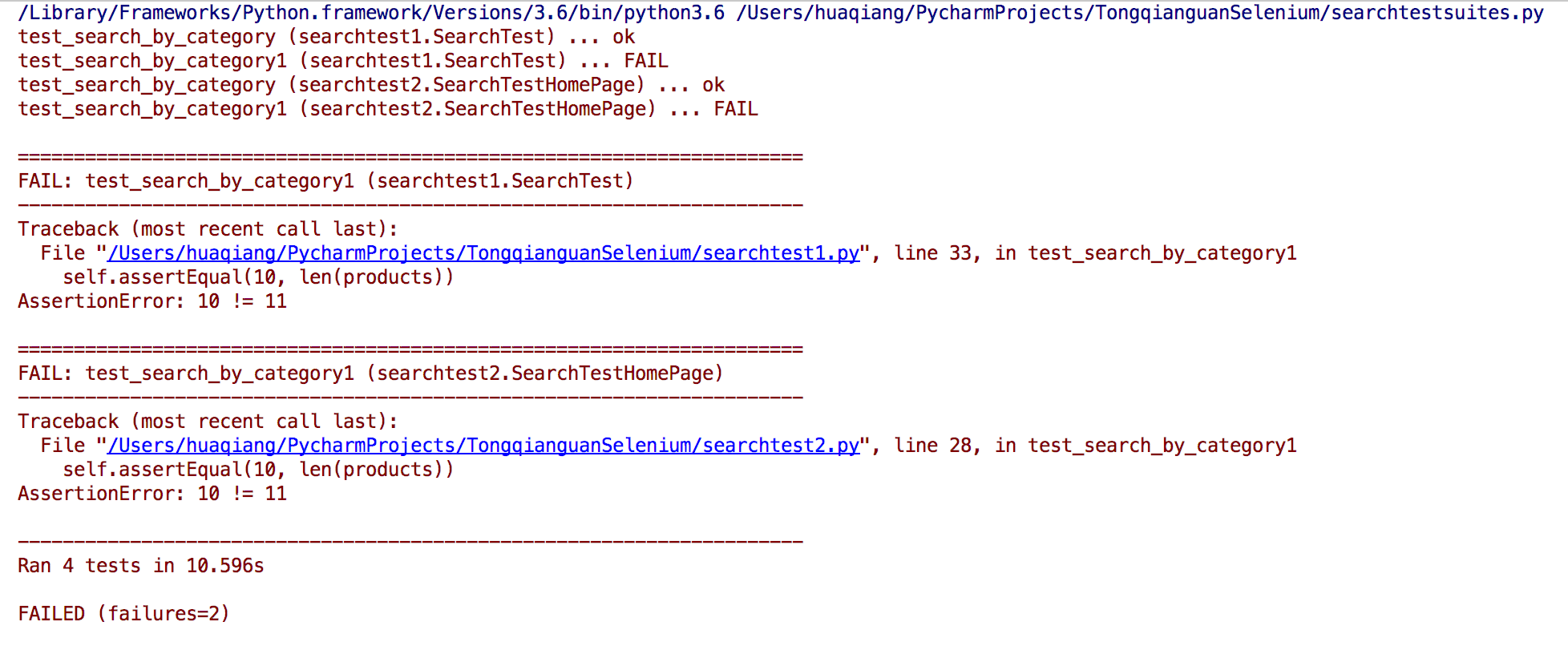
在这个脚本示例中:
我们使用TestSuites类来定义和执行测试套件,将多可测试加到一个测试套件中;还用TestLoader和TextTestRunner创建和运行测试套件;
2.6 使用unittest扩展来生成HTML格式的测试报告
基于之前的脚本示例,我们基本可以体会unittest的强大,但对于输出结果也许并不满意,我们可能需要生成一个所有测试的执行结果作为报告发给同组的其他人员;因此我们需要一个格式更加友好的测试报告,既能够查看测试结果,又能深入各个细节;
我们可以使用unittest的扩展HTMLTestRunner来实现;
现在我们来修改上一个示例脚本,并创建一个包含实际测试报告的输出文件:(searchtestsuiteshtml.py)
# -*- coding:utf-8 -*- import unittest import HTMLTestRunnerimport os from searchtest1 import SearchTestfrom searchtest2 import SearchTestHomePage from datetime import date now = date.today()datestr = now.strftime('%m-%d-%y') dir = os.getcwd() search_test = unittest.TestLoader().loadTestsFromTestCase(SearchTest)search_test_homepage = unittest.TestLoader().loadTestsFromTestCase(SearchTestHomePage) smoke_tests = unittest.TestSuite([search_test, search_test_homepage]) filepath = dir + "/SmokeTestReport{}.html".format(datestr)with open(filepath, 'wb') as outfile: runner = HTMLTestRunner.HTMLTestRunner(stream=outfile, title='Title:Test Report', description='Des:Smoke Tests') runner.run(smoke_tests)
将下载的脚本直接添加到工程使用可能会报错,这是因为现在的HTMLTestRunner对应的是Python2的版本;

可以在这里得到对应修改后的脚本文件;
运行脚本我们得到了一个SmokeTestReport06-08-18.html的输出文件:
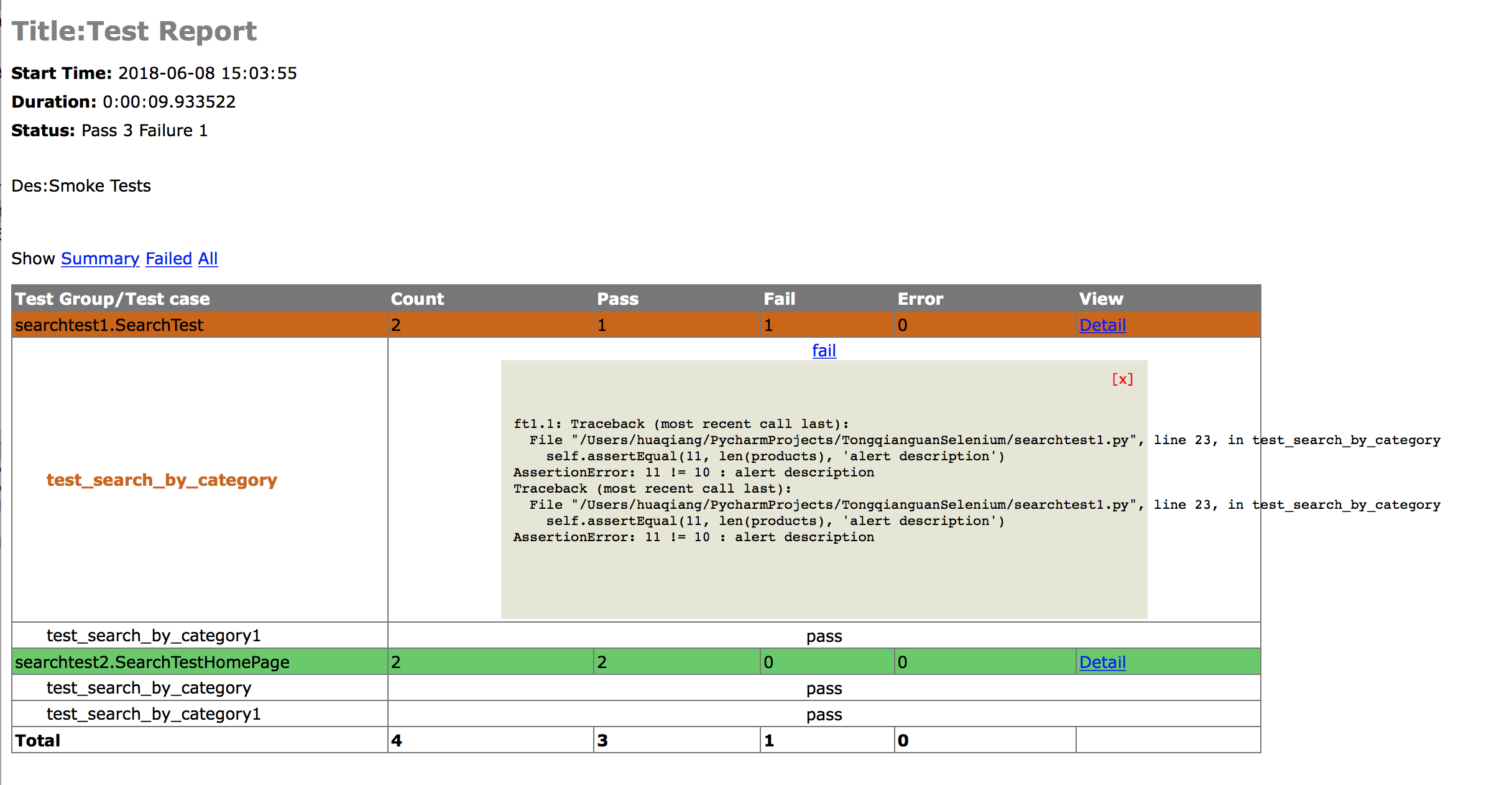
这就是我们预期生成的测试报告文件;
关于断言的使用,还很浅显,需要结合页面中不同类型的htnl元素进行断言,接下来学习如何定义和使用定位器来与之交互;
2.7 上述脚本中存在的问题
在后续和同事交流的实践中,我们发现了一个问题,在这里单独作为一个小节,简要说明下;
对于searchtest1.py这个脚本,由于第二个测试用例是复制的第一个,所以在运行的时候,我并没有发现什么不对,但是如果把第二个测试用例的搜索内容进行了修改,问题就会出现:重新submit之后的搜索结果并没有打印出来;
经过一番尝试和修改,新的脚本如下:
# -*- coding:utf-8 -*- import unittestfrom selenium import webdriver import time class SearchTest(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Firefox() cls.driver.implicitly_wait(15) cls.driver.maximize_window() cls.driver.get('http://www.baidu.com') def test_search_by_category(self): self.search_field = self.driver.find_element_by_id("kw") self.submit_field = self.driver.find_element_by_id("su") self.search_field.clear() self.search_field.send_keys('铜钱贯') self.submit_field.submit() products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") for product in products: print("1" + product.text) self.assertEqual(10, len(products), 'alert description tqg') def test_search_by_category1(self): self.search_field = self.driver.find_element_by_id("kw") self.submit_field = self.driver.find_element_by_id("su") self.search_field.clear() self.search_field.send_keys('路飞') self.submit_field.click() time.sleep(2) products = self.driver.find_elements_by_xpath("//div[contains(@class, 'c-abstract')]") for product in products: print("2" + product.text) self.assertEqual(6, len(products), 'alert description lufei') @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
问题出在:
对于当前页的搜索submit之后,结果没能返回的时候 就已经进行了断言,显然这是不对的;
我们修改使用搜索按钮的click()方法,然后导入time模块,调用sleep()方法强制等待2s,等待当前界面对“路飞”的搜索结束之后在进行断言;
相关联的,这个问题引入了等待响应的方式问题,我们后续学习;
小结-序
伴随着前两章内容的实践,我们了解到了一个基本的自动化测试脚本是如何编写、执行和使用的,我们要做的还有很多;接下来我们要学习更多高级的内容,包括元素定位、元素的等待机制等,在简单略读了整本参考书籍之后,还有很多优秀的第三方测试工具可以帮助我们更简单、更强大的实现测试需求,鉴于对正本书的内容有了一个整体的认识,我将调整接下来笔记的梳理方式,更多的结合实际的测试场景去总结和学习,也方便大家交流!
三、元素定位
页面元素:
web应用是包含 超文本标记语言(HTML)、层叠样式表(CSS)、JavaScript脚本组成的Web页面集合;
基于的用户交互有 跳转到指定的 统一资源定位(URL)网站,单击提交,向服务发送请求,处理服务器响应资源;
浏览器使用以上资源生成Web页面,构建Web视觉元素;如 文本框 按钮 标签页 图标 复选框 单选按钮 列表 图片等;
这些视觉元素或控件都被Selenium称为页面元素(WebElements);
本章我们需要掌握的是:Selenium WebDriver定位元素的方法;如何用浏览器开发者模式辅助定位元素;
定位元素的方法其实有很多:通过id、name、class属性定位,利用xpath和css选择器定位;在定位到元素之后,我们可以使用Selenium WebDriver与之自动化交互;
在前两章的学习过程中,我们已经使用过了一些元素定位的方法;在浏览器中我们可以通过查看元素/源文件的方式来查看页面结构;(具体的查询更多的是靠对html文档结构的熟悉,多多阅读前端页面,好处多多)
Safari的开发模式也是很好用的;
3.1 元素定位
为了模拟用户操作,我们需要告诉Selenium如何定位元素,如何查看元素的属性和状态;
这里再次将之前实践的针对百度搜索的较完整测试脚本拿过来进行说明;(TqgWebTestProject testBaiduSearch.py)
import unittestfrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver.common.by import By class BaiduSearchKeyword(unittest.TestCase): @classmethod def setUpClass(cls): cls.driver = webdriver.Firefox() cls.driver.implicitly_wait(5) cls.driver.maximize_window() cls.driver.get('http://www.baidu.com') def is_element_present(self, how, what): try: self.driver.find_element(by=how, value=what) except NoSuchElementException as e: return False return True def test_search_by_tqg_justify(self): self.assertTrue(self.is_element_present(By.ID, 'kw')) def test_search_by_tqg(self): self.search_field = self.driver.find_element_by_id('kw') self.submit_field = self.driver.find_element_by_id('su') self.search_field.clear() self.search_field.send_keys('铜钱贯') self.submit_field.click() products = self.driver.find_elements_by_xpath("//div[contains(@class,'c-abstract')]") self.assertTrue(self.driver.title.__contains__('铜钱贯')) for product in products: print("铜钱贯 查询结果:" + product.text) @classmethod def tearDownClass(cls): cls.driver.quit() if __name__ == '__main__': unittest.main(verbosity=2)
这个脚本之前已经学习过,很简单 两个测试用例分别是 校验元素是否存在 存在之后使用它进行搜索,断言搜索结果中包含搜索的指定关键字;
要搜索一个产品,需要先找到搜索框和搜索按钮,接着通过键盘输入要查询的关键字,最后用鼠标单击搜索按钮,提交搜索请求;
这是人工的操作,我们希望Selenium能模拟这个过程,这就需要我们程序化地告诉Selenium如何定位,模拟鼠标的动作等;
Selenium提供了很多find_element_by方法定位页面元素,正常定位的话,相应的WebElement实例会被返回,反之将抛出NoSuchElementException的异常;
Selenium还提供了多种find_elements_by方法去定位多个元素,返回的是list数组;
8种find_element_by方法:
——find_element_by_id()
——find_element_by_name()
——find_element_by_class_name()
——find_element_by_tag_name()
——find_element_by_xpath()
——find_element_by_css_selector()
——find_element_by_link_text()#标签之间的文本信息
——find_element_by_partial_link_text()
find_elements_by方法按照一定的标准返回一组元素:
——find_elements_by_id()
——find_elements_by_name()
——find_elements_by_class_name()
——find_elements_by_tag_name()
——find_elements_by_xpath()
——find_elements_by_css_selector()
——find_elements_by_link_text()
——find_elements_by_partial_link_text()
我们可以通过浏览器产看html页面元素,找到搜索框(参照之前脚本):
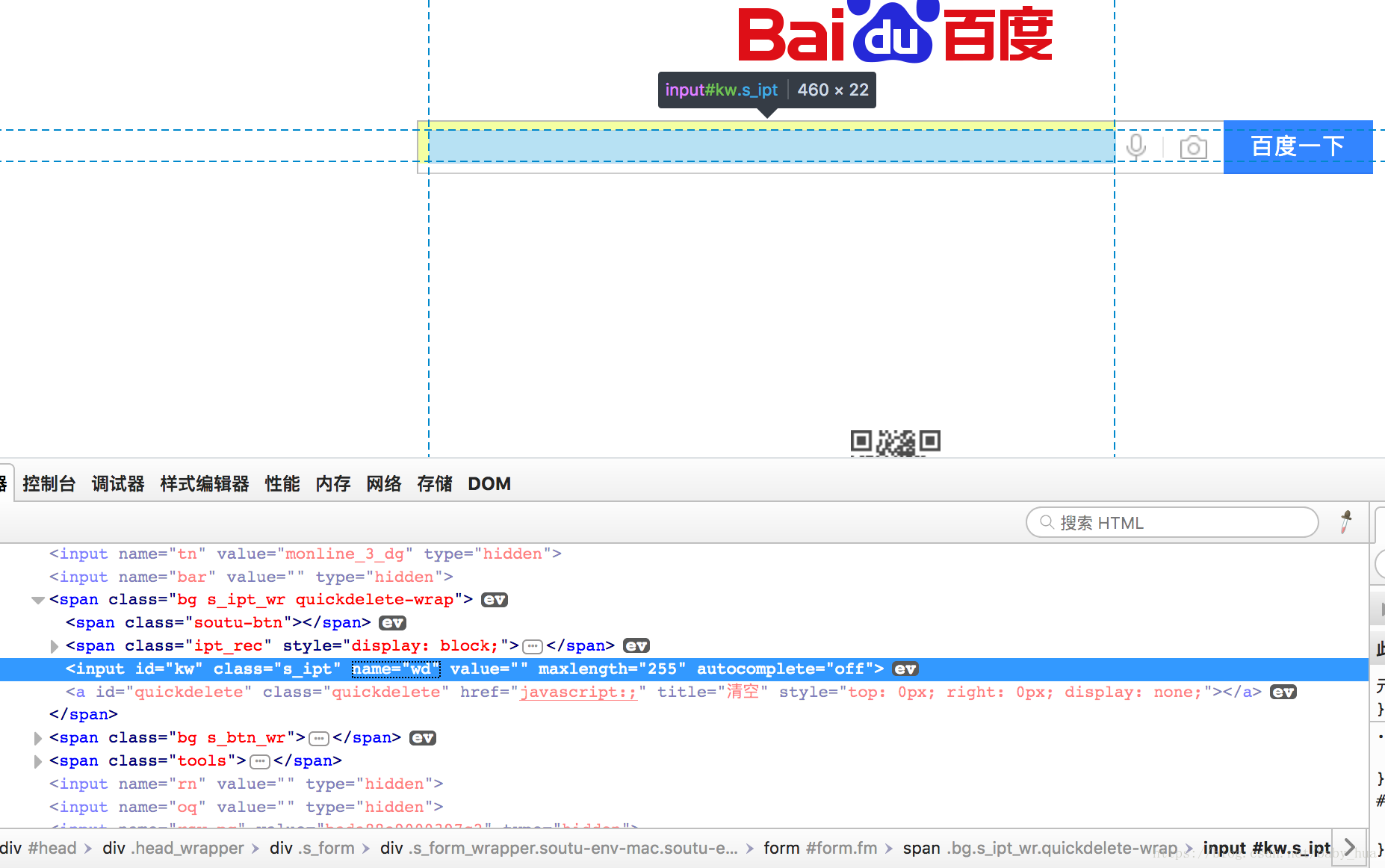
值得一提的是class定位:
class属性是用来关联CSS中定义的属性的;
通过对元素ID、name、class属性来查找元素是最为普遍和快捷的方法;
也可以增加一个测试用例断言元素的可用性:
def test_search_by_tqg_enable(self): self.submit_field = self.driver.find_element_by_id('su')
EndFragment
欢迎来到testingpai.com!
注册 关于