一、文件概述
1. 什么是文件
计算机文件是一个存储在存储器上的数据序列,可以包含任何数据内容。
概念上,文件是数据的集合和抽象。
用文件形式组织和表达数据更有效也更为灵活。
文件包括两种类型:文本文件和二进制文件。
文件本质上都是存储在存储器上的二进制数据。
使用HexEditor可以以16进制的方式打开任何文件。
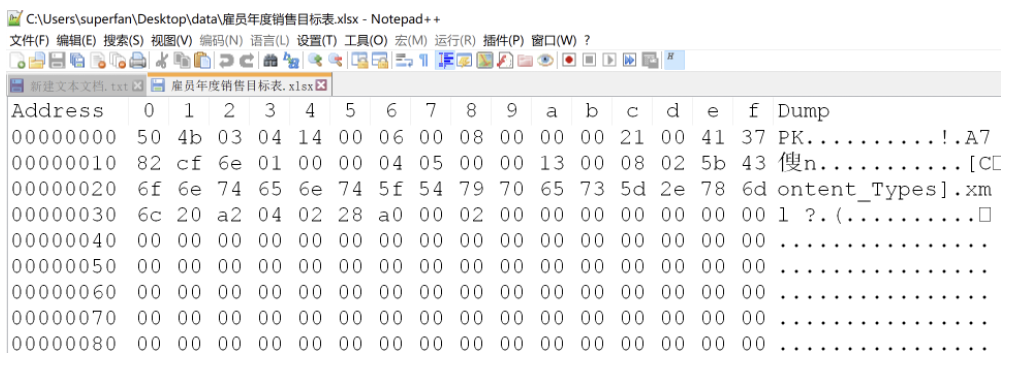
特别的文本文件遵循统一的字符编码,在打开时,计算机会根据字符编码解析成编码表上对应的字符。
二进制文件和文本文件本质上没有区别,只是没有统一的编码,需要根据特定的程序进行解析和运行。
无论是文本文件还是二进制文件都可以用"文本文件方式"和"二进制文件方式"打开,打开后的操作不同。
2.字符编码
计算机底层只能表示二进制信息,不能直接表示文字。计算机显示给我们看的文字可以看做是很小的一张张字符的图片。但如果文字都以图片进行存储和传输,图片体积非常大,从而效率会变得很低。
所以计算机科学家将这些单个字符图片放到一个文件中,这个文件就是字体文件。再给每个字符一个编号,存储传输时就用字符的编号。这个编号表就是字符编码(简单这么理解)。
文本文件存储的就是每个字符的编号,计算机在打开文本文件时,会根据指定的编码,去编码表中查询一个一个的字符,再渲染给用户。
2.1 ascii码
因为历史原因,字符编码有很多。最先发明的是ascii码。
总共127个字符,因此使用一个字节(8位二进制)来表示,也即是一个字符占一个字节的大小。
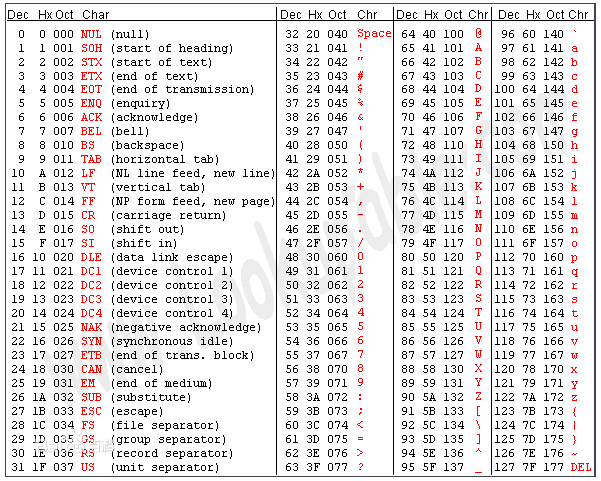
在记事本中键入abc123+-*/,然后使用HexEditor打开后发现跟上面的编码表是一致的。

2.2 gb2312
可以看到ascii码里只有英文字母和常见字符,没有中文,以及世界上其他国家的文字。随着计算机的发展,各国都创建了自己国家的计算机字符编码。
1980年中国发布了gb2312, GB2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成。
gb2312使用两个字节表示一个汉字。
通过字符串的encode方法可以根据字符编码进行编码
'中'.encode('gb2312')
b'\xd6\xd0'
2.3 gbk
GB2312的出现,基本满足了汉字的计算机处理需要,但对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。
GBK即汉字内码扩展规范,K为扩展的汉语拼音中“扩”字的声母。GBK编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。
gbk也是使用两个字节表示一个汉字。
'中'.encode('gbk')
b'\xd6\xd0'
'囙'.encode('gb2312')
UnicodeEncodeError Traceback (most recent call last)
in
----> 1 '囙'.encode('gb2312')
UnicodeEncodeError: 'gb2312' codec can't encode character '\u56d9' in position 0: illegal multibyte sequence
'囙'.encode('gbk')
b'\x87\xe0'
unicode
世界上存在着多种编码方式,同一个编码值,在不同的编码体系里代表着不同的字。要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。
我上大学时玩电脑游戏最大的问题就是乱码。
以日文的编码方式创建一个文本文件写入やめて,然后用记事本打开会显示如下:

这个问题促使了unicode码的诞生。
unicode将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。
Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。
将之前写有abc123+-*\的文件用记事本另存为unicode会发现文件的体积大了一倍。(本来应该是4倍,windows做了优化)
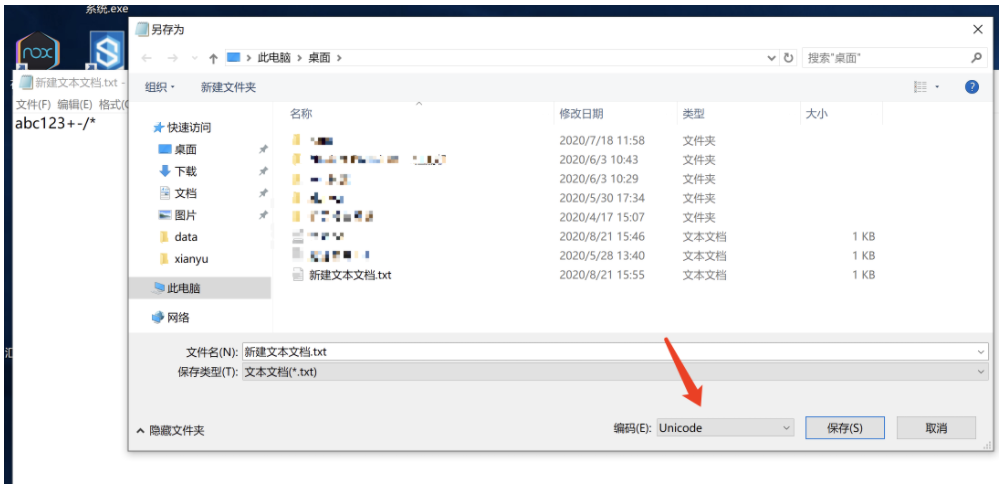
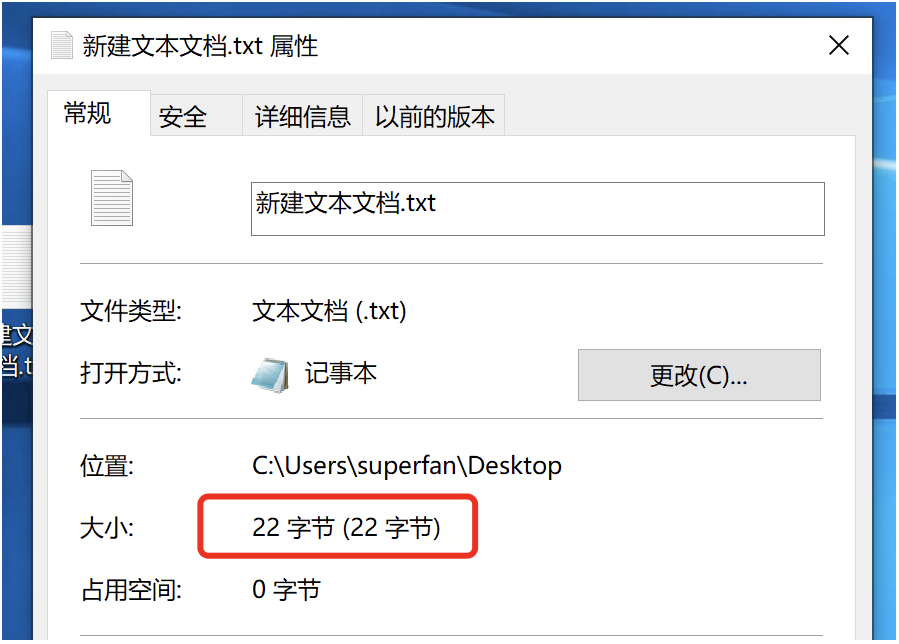
utf-8
为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。"汉"字的Unicode编码是U+00006C49,然后把U+00006C49通过UTF-8编码器进行编码,最后输出的UTF-8编码是E6B189。utf-8中汉字使用3个字节存储。
'a'.encode('utf-8')
b'a'
'中'.encode('utf-8')
b'\xe4\xb8\xad'
注意为了统一python3在内存中所有的字符都采用unicode。
二、python操作文件
python提供内置函数open()实现对文件的操作。
python对文本文件和二进制文件采用统一的操作步骤,和把大象放冰箱里的一样分三步,"打开-操作-关闭。"
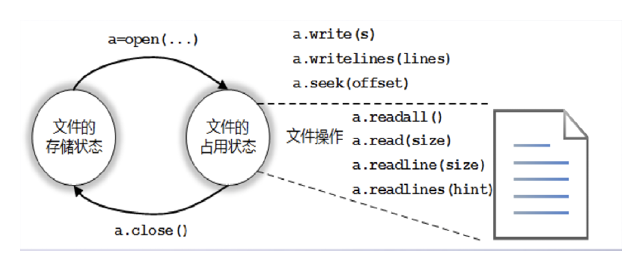
1. open函数
open(file, mode='r', encoding=None)
打开文件并返回对应的file object。如果该文件不能打开,则触发OSError。
- file 包含文件名的字符串,可以是绝对路径,可以是相对路径。
- mode 一个可选字符串,用于指定打开文件的模式。默认值
r表示文本读。 - encoding 文本模式下指定文件的字符编码
mode的取值:
| 字符 | 意义 |
|---|---|
'r' |
文本读取(默认) |
'w' |
文本写入,并先清空文件(慎用),文件不存在则创建 |
'x' |
文本写,排它性创建,如果文件已存在则失败 |
'a' |
文本写,如果文件存在则在末尾追加,不存在则创建 |
和mode组合的字符
| 字符 | 意义 |
|---|---|
'b' |
二进制模式,例如:'rb'表示二进制读 |
't' |
文本模式(默认),例如:rt一般省略t |
'+' |
读取与写入,例如:'r+' 表示同时读写 |
2.读文本文件
在当前目录下创建一个名为test.txt的文本文件,(注意编码方式)文件中写入下面的内容:
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
2.1操作基本步骤
# 打开文件 mode=rt,t可以省略
fb = open('test.txt', 'r', encoding='utf-8')
# 读取
content = fb.read()
print(content)
# 关闭文件
fb.close()
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
上面这种操作经常会忘记关闭文件句柄,造成资源浪费,所以处理文件是往往使用with语句进行上下文管理。
2.2 with 上下文管理
with open('test.txt', 'r', encoding='utf-8') as fb:
content = fb.read()
print(content)
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
with语句执行完毕会自动关闭文件句柄。
2.3 相对路径与绝对路径
进行文件处理时经常会碰到相对路径和绝对路径的问题。
绝对路径好理解,它指定了文件在电脑中的具体位置,以windows电脑为例:
d:\lemon\课件\python入门.md
相对路径一般是指相对当前脚本的路径,比如上面的案例中的test.txt因为和当前脚本在同一个文件夹下,所以可以直接使用test.txt作为文件名来操作。
也可显式的表达当前路径./test.txt,./表示当前目录。
../表示上级目录,同理../../表示上上级目录,依此类推。
那什么时候使用相对路径,什么时候使用绝对路径呢。
一般情况下项目本身的资源文件和脚本路径相对固定,为了不影响项目的移植性,必须使用相对路径。
如果需要读取操作系统中固定位置的系统文件一般使用绝对路径。
2.4 逐行读取
在读取文本文件时,经常需要按行读取,文件对象提供了多种方法进行按行读取。
- readline
从文件中读取一行;如果 f.readline() 返回一个空的字符串,则表示已经到达了文件末尾
with open('test.txt', 'r', encoding='utf-8') as fb:
print(fb.readline())
print(fb.readline())
print(fb.readline())
print(fb.readline())
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
- readlines
以列表的形式返回文件中所有的行。
with open('test.txt', 'r', encoding='utf-8') as fb:
content = fb.readlines()
print(content)
['静夜思\n', '床前明月光,疑是地上霜。\n', '举头望明月,低头思故乡。']
- 迭代
要从文件中读取行,还可以循环遍历文件对象。这是内存高效,快速的,并简化代码:
# 5星推荐
with open('test.txt', 'r', encoding='utf-8') as fb:
for line in fb:
print(line)
静夜思
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
3.读二进制文件
任何文件都可以以二进制读的方式打开,读取test.txt的二进制内容。
# mode=rb,不需要encoding参数
with open('test.txt', 'rb') as fb:
content = fb.read()
print(content)
b'\xe9\x9d\x99\xe5\xa4\x9c\xe6\x80\x9d\n\xe5\xba\x8a\xe5\x89\x8d\xe6\x98\x8e\xe6\x9c\x88\xe5\x85\x89\xef\xbc\x8c\xe7\x96\x91\xe6\x98\xaf\xe5\x9c\xb0\xe4\xb8\x8a\xe9\x9c\x9c\xe3\x80\x82\n\xe4\xb8\xbe\xe5\xa4\xb4\xe6\x9c\x9b\xe6\x98\x8e\xe6\x9c\x88\xef\xbc\x8c\xe4\xbd\x8e\xe5\xa4\xb4\xe6\x80\x9d\xe6\x95\x85\xe4\xb9\xa1\xe3\x80\x82'
# 也可以逐行读取,以\n换行符标志
with open('test.txt', 'rb') as fb:
for line in fb:
print(line)
b'\xe9\x9d\x99\xe5\xa4\x9c\xe6\x80\x9d\n'
b'\xe5\xba\x8a\xe5\x89\x8d\xe6\x98\x8e\xe6\x9c\x88\xe5\x85\x89\xef\xbc\x8c\xe7\x96\x91\xe6\x98\xaf\xe5\x9c\xb0\xe4\xb8\x8a\xe9\x9c\x9c\xe3\x80\x82\n'
b'\xe4\xb8\xbe\xe5\xa4\xb4\xe6\x9c\x9b\xe6\x98\x8e\xe6\x9c\x88\xef\xbc\x8c\xe4\xbd\x8e\xe5\xa4\xb4\xe6\x80\x9d\xe6\x95\x85\xe4\xb9\xa1\xe3\x80\x82'
4. 写文本文件
4.1 清除写w
案例:将锄禾这首诗写入test.txt文件中
# mode=w 没有文件就创建,有就清除内容,小心使用
with open('test.txt', 'w', encoding='utf-8') as fb:
fb.write('锄禾\n')
fb.write('锄禾日当午,汗滴禾下土;\n')
fb.write('谁知盘中餐,粒粒皆辛苦。\n')
运行后会发现之前写有静夜思的test.txt内容修改为锄禾,因为w模式会清除原文件内容,所以小心使用。
4.2 追加写 a
案例:将静夜思这首诗追加到test.txt文件中
# mode=a 追加到文件的最后
with open('test.txt', 'a', encoding='utf-8') as fb:
fb.write('静夜思\n床前明月光,疑是地上霜;\n举头望明月,低头思故乡。\n')
4.3 排他写x
案例:在当前目录中创建文件test.txt,存在则不创建
# mode=x
try:
with open('test.txt', 'x', encoding='utf-8') as fb:
fb.write('')
except Exception as e:
print(e)
[Errno 17] File exists: 'test.txt'
5.写二进制文件
在写模式后加b即是写二进制模式,这种模式下写入内容为字节数据。
例如:将爬到的图片二进制信息写入文件中。
import requests
url = 'https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1247698508,1430079989&fm=26&gp=0.jpg'
response = requests.get(url)
with open('校花.jpg', 'wb') as f:
f.write(response.content)
6.读写文件
有时候需要能够同时读写文件,在模式后面加上+号即可给读模式添加写,给写模式添加读。
with open('test.txt', 'r+', encoding='utf-8') as f:
# 读文件
print(f.read())
f.write('草\n离离原上草,一岁一枯荣;\n野火烧不尽,春风吹又生!\n')
锄禾
锄禾日当午,汗滴禾下土;
谁知盘中餐,粒粒皆辛苦。
静夜思
床前明月光,疑是地上霜;
举头望明月,低头思故乡。
7.案例:python处理解析csv文件
# 读取csv文件并解析为嵌套列表
data = []
with open('鸢尾.csv', 'r', encoding='gbk') as f:
for line in f:
# 去掉换行符
line = line.strip()
data.append(line.split(','))
data
# 将数据写为csv文件
with open('test.csv', 'w', encoding='utf-8') as f:
for item in data:
f.write(','.join(item) + '\n')
8.文件指针
open函数返回的文件对象使用文件指针来记录当前在文件中的位置。
8.1 read方法
在读模式下,使用文件对象的read方法可以读取文件的内容。它接收一个整数参数表示读取内容的大小,文本模式下表示字符数量,二进制模式下表示字节大小。
with open('test.txt', 'r', encoding='utf-8') as f:
content = f.read(3)
print(content)
锄禾
content # 三个字符
'锄禾\n'
with open('test.txt', 'rb') as f:
content = f.read(3)
print(content)
b'\xe9\x94\x84'
'锄'.encode('utf-8') # 三个字节
b'\xe9\x94\x84'
当以读的方式打开文件后文件指针指向文件开头,执行read操作之后,根据读取的数据大小指针移动到对应的位置。
8.2 tell方法
文件对象的tell方法返回整数,表示文件指针距离文件开头的字节数。
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.tell())
content = f.read(3)
print(content)
print(f.tell())
0
锄禾
7
content.encode('utf-8')
b'\xe9\x94\x84\xe7\xa6\xbe\n'
r模式打开文件后文件指针指向文件开头,执行read操作之后,根据读取的数据大小指针移动到对应的位置。
with open('test.txt', 'a', encoding='utf-8') as f:
print(f.tell())
243
a模式打开文件后文件指针指向文件末尾。
8.3 seek方法
通过文件对象的seek方法可以移动文件句柄
seek方法接收两个参数:
- offset 表示偏移指针的字节数
- whence 表示偏移参考,默认为0
- 0 表示偏移参考文件的开头,offset必须是>=0的整数
- 1 表示偏移参考当前位置,offset可以是负数
- 2 表示偏移参考文件的结尾,offset一般是负数
注意文本模式下只允许从文件的开头进行偏移,也即只支持whence=0
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.read(3))
# 跳转到文件开头
f.seek(0)
# 再读取第一个字
print(f.read(1))
锄禾
锄
with open('test.txt', 'rb') as f:
# 读取文件最后的10字节
f.seek(-10,2)
print(f.read())
b'\xe5\x8f\x88\xe7\x94\x9f\xef\xbc\x81\n'
欢迎来到testingpai.com!
注册 关于