冒泡排序,是比较简单的一种排序算法。它的命名源于它的算法原理:重复的从前往后(或者从后往前),依次比较记录中相邻的两个元素,如果他们顺序错误就把它们交换过来,直到没有再需要交换的元素,就说明该记录已完成排序。它看起来就像是把最大的元素(或最小的元素)经由交换慢慢的‘浮’到数列的顶端,故名冒泡排序。
算法原理
我们通过将一个无序数列按升序排序来演示算法原理。
算法流程:1. 比较相邻元素,如果第一个比第二个大,就交换它们两个。
2. 对每一组相邻元素做同样的工作,从开始到最后一对,这时最后的元素应该会是最大的数。
3. 针对所有元素重复步骤1,2,除了最后一个元素,这时倒数第二个元素应该会是第二大的数。
4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
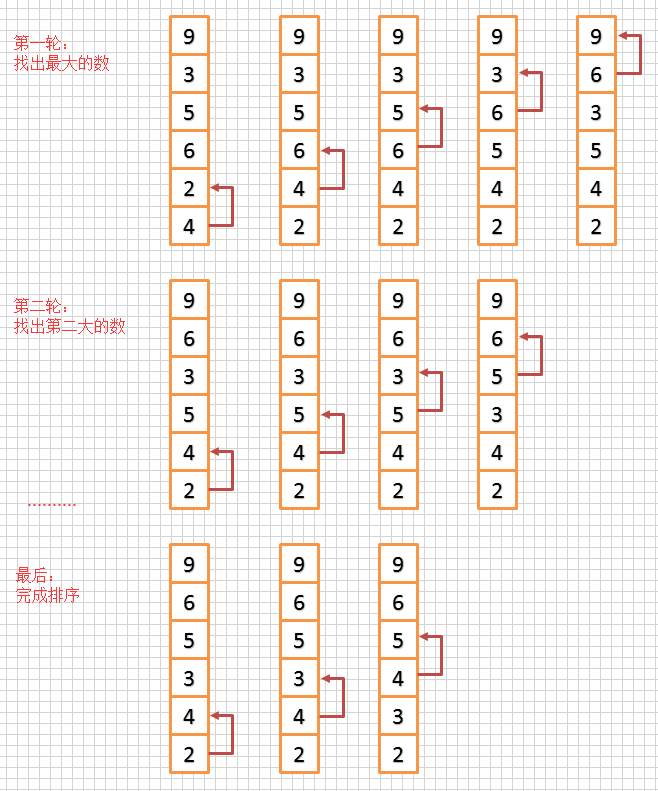
图解步骤:
有一个数列 [4, 2, 6, 5, 3, 9],通过冒泡排序的步骤如下:
代码实现
总结:
- 一个长度为n的数列,我们最多需要进行n-1轮比较
- 第m轮,需要n-m-1次比较
根据上述思想,使用python代码来实现:
l = [1, 7, 5, 6, 2, 8, 3, 9, 4]
n = len(l)
for m in range(n-1): # 外层循环决定需要排序的轮次
for i in range(n-m-1): # 内层循环决定要比较的次数
if l[i] > l[i+1]:
l[i], l[i+1] = l[i+1], l[i]
print(l)
输出结果:
[1, 5, 6, 2, 7, 3, 8, 4, 9]
[1, 5, 2, 6, 3, 7, 4, 8, 9]
[1, 2, 5, 3, 6, 4, 7, 8, 9]
[1, 2, 3, 5, 4, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9] # 到这里其实已经排序结束了
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
可以看到,循环进行了5次就得到了正确的结果,但是程序还是进行了剩下的循环。对上面的程序进行优化,得到下面的改进版。
l = [1, 7, 5, 6, 2, 8, 3, 9, 4]
n = len(l)
for m in range(n-1):
flag = True # 设置一个标志位
for i in range(n-m-1):
if l[i] > l[i+1]:
l[i], l[i+1] = l[i+1], l[i]
flag = False # 如果本能循环还需要交换就改变flag的值
if flag: # 如果flag没有改变就说明排序成功了
break
print(l)
运行结果:
[1, 5, 6, 2, 7, 3, 8, 4, 9]
[1, 5, 2, 6, 3, 7, 4, 8, 9]
[1, 2, 5, 3, 6, 4, 7, 8, 9]
[1, 2, 3, 5, 4, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
分析总结
1. 时间复杂度
- 若列表的初始状态是正序的,一趟扫描即可完成排序。所需的比较次数C和移动次数M均为最小值:
C=n-1,M=0,所以冒泡排序的最好时间复杂度为O(n) - 若列表的初始状态是反序的,需要进行n-1趟排序。每趟排序要进行n-i次比较,且每次比较都必须移动记录2次来达到交换记录的位置。在这种情况下比较和移动次数均达到最大值
C = n(n-1)/2=O(n2),M=2n(n-1)/2=O(n2)
冒泡排序的最坏时间复杂度为O(n2)
综上,冒泡排序的平均时间复杂度为O(n2)
2. 空间复杂度
冒泡排序算法过程中内存空间稳定,所以空间复杂度为O(1)
3. 稳定性分析
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,是不会再交换的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
4. 应用分析
因为冒泡排序的时间复杂度为O(n2),一般应用于小规模数据的排序。且冒泡排序逻辑比较简单,易于理解,一般会用于教学。
欢迎来到testingpai.com!
注册 关于