目前为止学习到的一些数据查找匹配方法有很多相似点,可能容易混淆,所以写了这篇文章,梳理巩固相关知识,方便后续查阅。同时期待同行们的指正和补充。
一、JsonPath
作用
JsonPath 是一种信息抽取类库,用来解析多层嵌套的json数据格式。在接口测试等业务中,需要从返回的json数据中筛选或提取某个字段进行断言等操作(本文仅使用python语言实现)
用法
首先需要安装JsonPath模块:pip install jsonpath
官方文档:http://goessner.net/articles/JsonPath
import jsonpath #首先导入jsonpath模块
#假设存在response这样一串json数据
response ={
"teacher":{
"name":"李小二",
"sex":"男",
"age":30,
"height":185.5,
"teacher":"递归搜索测试" },
"class_one":{
"students":[
{
"name":"张一",
"sex":"男",
"age":18,
"height":170.5 },
{
"name":"张二",
"sex":"女",
"age":20,
"height":160.5}]}}
# 提取出来的是list,提取根节点下的teacher字段的值
res1 = jsonpath.jsonpath(response,"$.teacher")
print(res1)
res2 = jsonpath.jsonpath(response,"$[teacher]")
print(res2)
# 提取指定的值
res3 = jsonpath.jsonpath(response,"$.teacher.name")
print(res3)
res4 = jsonpath.jsonpath(response,"$[teacher][name]")
print(res4)
# 递归提取,获取能匹配的所有字段,返回list
res5 = jsonpath.jsonpath(response,"$..name")
print(res5)
# 条件筛选
res6 = jsonpath.jsonpath(response,"$..[?(@.age>18)]")
print(res6)
补充:筛选匹配规则可以在代码中写死,也可以在excel等文件中新建字段保存,代码中需要时则读取引入
二、Xpath
作用
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力(从上至下查找)。
在web自动化中可以作为万能的定位方式:可通过文本内容定位,可跟进元素的多个组合特征条件筛选定位,可根据元素的层级定位等
用法
1.绝对路径

从html开始,以斜杠 / 开头,每一个元素层级关系都会罗列出来(和用户看到的页面元素顺序不同)
同级的元素位置从数字1开始,如 div[1]
可使用右键copy完整的xpath路径查看,比如 /html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
但是web自动化工作中一般不使用这种方式,因为太过于依赖当前页面结构,一旦页面结构发生变动,之前写的路径可能就失效了。
2.相对路径
与绝对路径的表达相比,是以双斜杠 // 开头,在xml树中从上至下查找任意位置双斜杠后的元素
通过标签名筛选:
//标签名 如: //a
通过标签名+属性筛选:
//标签名[@属性=值] 如: //input[@name="wd"]
通过标签名+文本内容筛选:
//标签名[text()=值] 如: //p[text()="已签到"]
通过contains()匹配部分属性值或者部分文本内容:
//标签名[contains(@属性/text(),要包含的值)]
如:
//input[contains(@class,"s_btn")]
//a[contains(text(),"123")]
逻辑运算:and or
//标签名[@属性=值 and @属性=值 and @属性=值]
//标签名[text()=值 and @属性=值]
//标签名[contains(@属性/text(),要包含的值) and @属性=值]
(1)从上到下的层级定位
//表达式1//表达式2 --- 第二个//,是在第一个//表达式1找到的元素的子孙后代当中去定位。
//表达式1/表达式2 --- 第二个/,是在第一个//表达式1找到的元素的儿子当中去定位。
//div[@id="u1"]//a
//div[@id="u1"]/a
(2)轴定位
可以用于定位会改变的元素
通过子孙元素,找父元素、祖先元素。
通过兄弟姐妹元素,找元素。
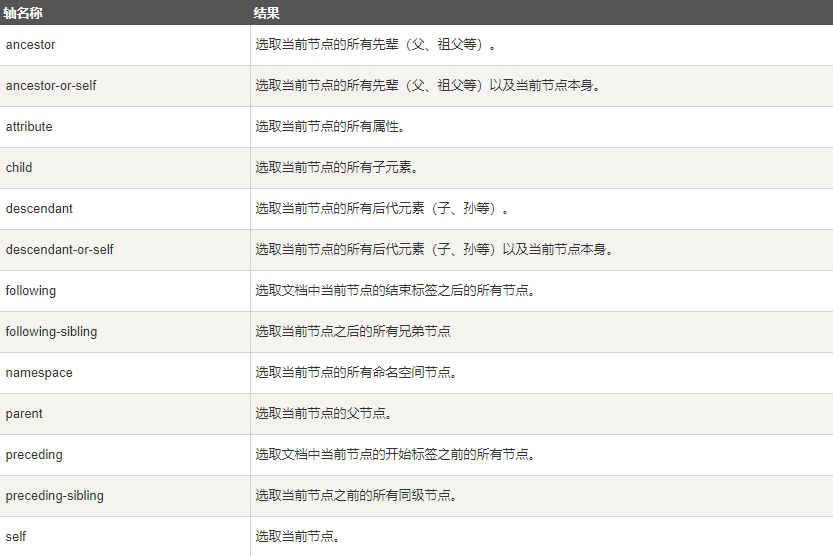
使用语法:
已知的元素/轴名称::标签名称[@属性=值]
例:
//div//table//td//preceding::td
//span[contains(text(),"发布时间")]/parent::div/preceding-sibling::h6
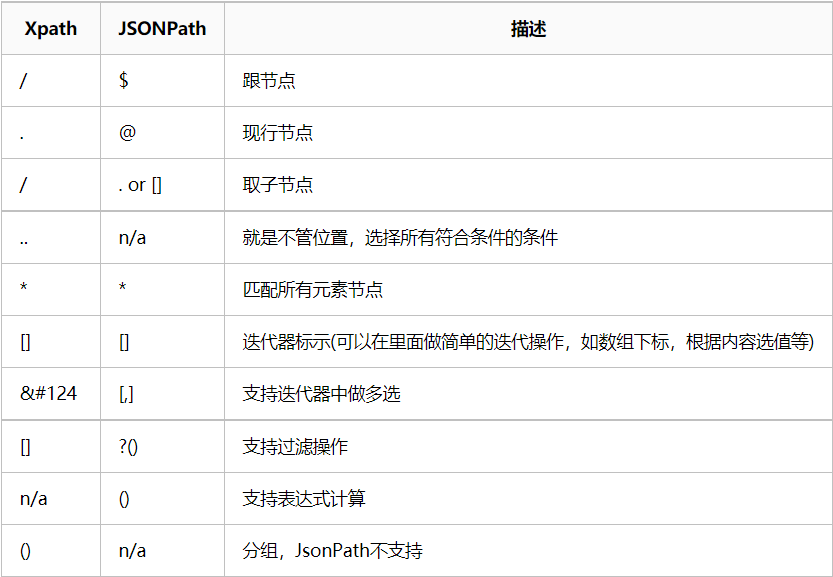
3.与JsonPath对比
三、正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
在python中需要先安装 re 模块 pip install re
在Notepad等文本编辑器中也可以直接使用正则表达式对文本进行匹配查找,批量修改等操作
符号含义:
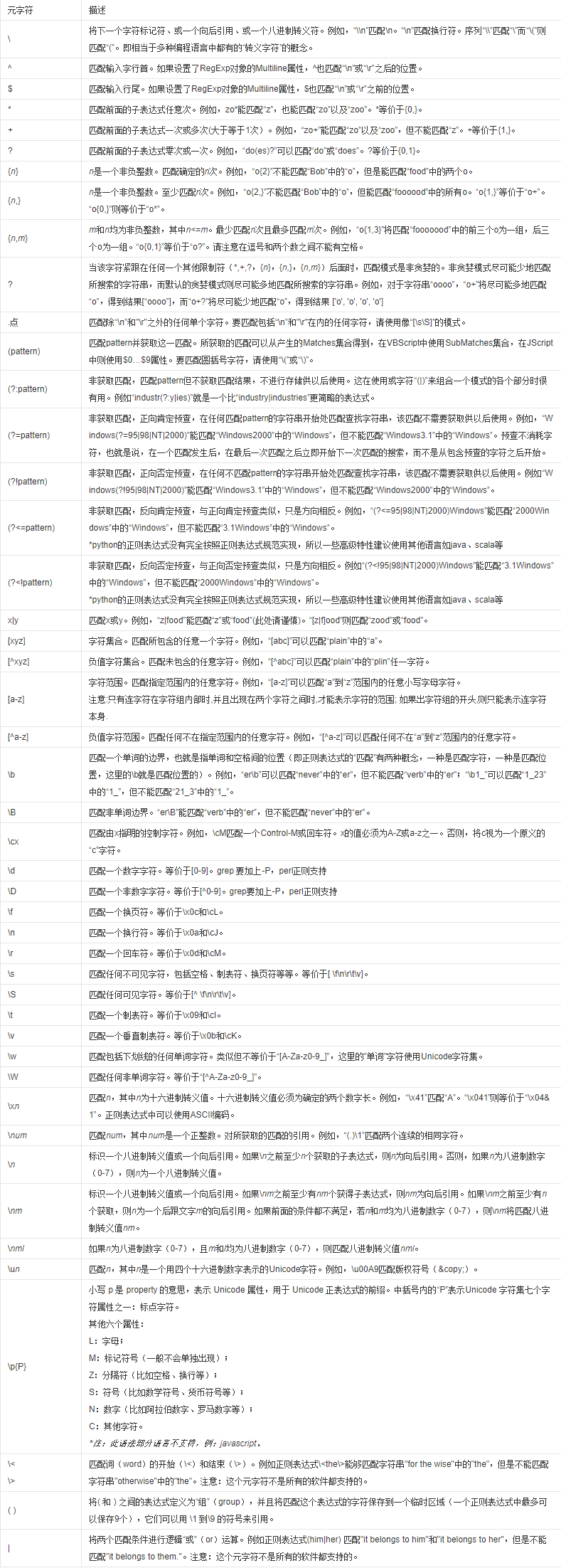
可参考百度百科:https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin
在python中的用法:
欢迎来到testingpai.com!
注册 关于